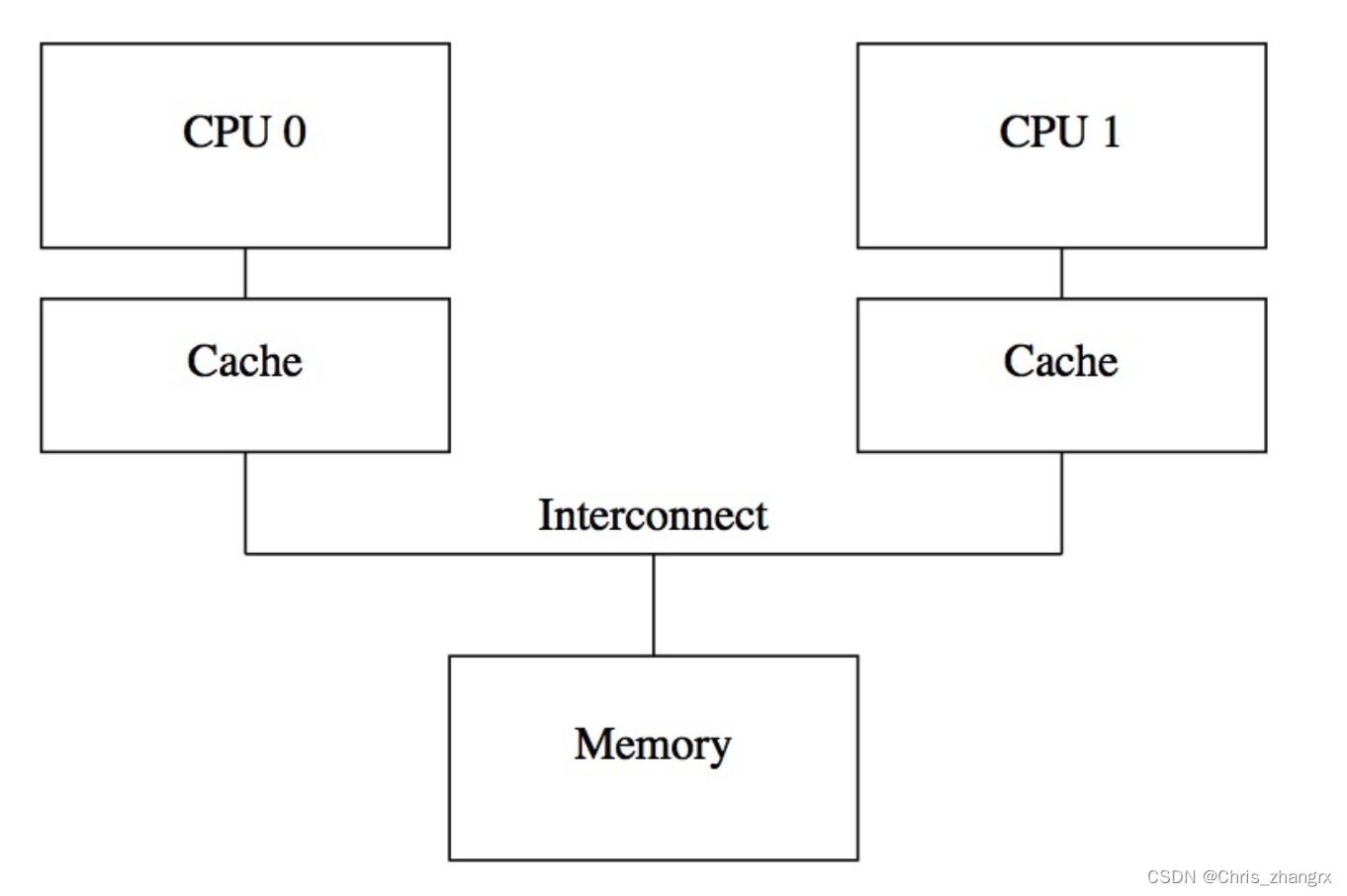
Memory model
In the case where the compiler and the actual hardware execution stages are out-of-order, and the CPU is multithreaded, the memory model is:
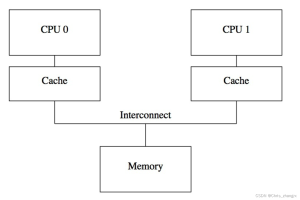
This involves the issue of memory data consistency between different CPU cores. To ensure that in the case of out-of-order. touch screen hmi
typedef enum memory_order {
memory_order_relaxed = __mo_relaxed,
memory_order_consume = __mo_consume,
memory_order_acquire = __mo_acquire,
memory_order_release = __mo_release,
memory_order_acq_rel = __mo_acq_rel,
memory_order_seq_cst = __mo_seq_cst,
} memory_order;
The memory order model in the 6 above is defined in C++ atom. It mainly intervenes in the rearrangement intervention on the assembly and the disorderly order on the hardware, and the visibility of the execution results in multiple cores.
Core is divided into memory unit, control unit and operation unit, when the load instruction, the alu operation unit is idle, so when taking the value in advance to do the next instruction. This introduces the store buffer hardware unit for data synchronization between core and L1, and the invalidate queue hardware unit for synchronizing data between different L1 caches. In order to get a response immediately after the notification, it will not be empty, but this design also has a price. At this time, it is necessary to impose some constraints on the order of execution of the relevant data by the programmer in the software.
store buffer
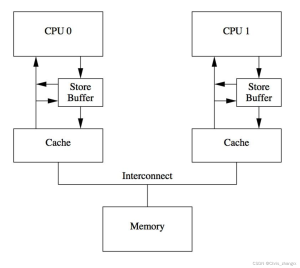
core0 after performing the store operation, the store operation corresponding to the cacheline will send an invalidate message between other cores, and wait until the other cores have done invalidate ack before continuing to execute, then during this period core0 can only be in the blind stage, core0 really need to wait so long? The hardware designer introduced the hardware structure of the store buffer, so that when core0 performs store operations, the value will enter the store buffer first, and there is no need to immediately send invalidate messages to other cores. Writing to the store buffer requires only 1 clock cycle, and writing to the L1 cache requires basically 3 cycles. But this raises two questions:
For the function are all running on the same core, if the new value of the same variable is first store in the store buffer, but there is also an old value in the cache, when performing the load variable operation, you need to go to the store buffer to find the corresponding memory location, if you find it, use the new value.
For the function running on different cores, there are dependencies between the data, and the CPU hardware design level can not determine whether the variables currently processed by the core are related to other cores, the CPU execution is considered to be a single-threaded program, the presence of multiple threads is not perceived, then the coder needs to tell the CPU that the store buffer flush to the cache now, so the CPU designer provides a memory called barrier’s tools.
void foo(void) {
a=1;
smp_mb(); // memory barrier
b=1;
}
void bar(void) {
while (b == 0) continue;
assert(a == 1);
}
smp_mb will flush all the data in the store buffer into the cache when executing, so that the execution will be successful.
invalidate queue
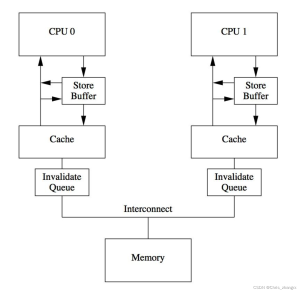
Earlier introduced store buffer to help core in the store operation as soon as possible to return, here buffer and cache are hardware elements, so the general memory is relatively small (dozens of bytes), when the store buffer is full, you need to flush the buffer memory into the cache, after the refresh will trigger the cacheline’s invalidate message, these messages It is sent to the other cores together, and then waits until the other cores return invalidate ack before proceeding to further execution. If these cores are not processed in a timely manner, it will cause the core to wait for idleness. So add an invalidate queue hardware structure, similar to the store buffer, with the invalidate queue, the sent invalidate message only needs to push into the queue of the corresponding core, and then the core will immediately return the corresponding invalidate ack, there is no need to wait in between.
But this also brings some problems.
void foo(void) {
a=1;
smp_mb(); // memory barrier
b=1;
}
void bar(void) {
while (b == 0) continue;
// smp_mb(); // 也需要加入 memory_barrier
assert(a == 1);
}
Add core0 to run the foo function, core1 to run the bar function. When smp_mb() is called in core0 to refresh the store buffer, after the invalidate message is given to core1, then run b =1. core1’s bar function will determine that b == 0 fails and then execute assert, but if the invalidate queue in core1 has not yet brushed to core1’s cache, assert will still fail. So you need to add a memory barrier before assert. This memory barrier will refresh both the store buffer and the invalidate queue.
memory barrier
The smp_mb() mentioned above is a full memory barrier that refreshes both the store buffer and the invalidate queue, and the hardware designer introduced:
Read memory barrier refreshes the invalidate queue
The write memory barrier refreshes the store buffer
Sequential Model (SC)
The sequential consistency model is short for SC, and the multicore read-write cache is synchronized using the MESI protocol. Under the sequential model, the expected execution of multithreaded operations is consistent and memory access is not out of order.
Core 0 Core 1
S1: Store data = New;
S2: Store flag = SET; L1: Load r1 = flag;
B1: if(r1≠SET) goto L1;
L2: Load r2 = data;
The following instructions will be run in the order of S1→S2→ L1→ L2. Its characteristic is that the execution behavior of the instruction is consistent with that of the single core.
Full Storage Sequencing (TSO)
S1:Store flag = set
S2:load r1 = data
S3:store b = set
The sequential model is S1→S2→ S3, but after adding the sb structure, S1 puts the instruction to sb and returns immediately, at which time the S2, read instruction will be executed immediately, and the CPU must wait for the data to be read to r1 before continuing execution. Total store order is that sb results must be sent to the main memory in the exact order of the FIFO. There is a limitation here, in order to ensure data consistency, S3 must be executed after S1, and S1’s data must be written to the cache. There is nothing wrong with a single core, but in a multi-core case, data interdependence can be problematic.
Core 0 Core 1
S1: store data = NEW
S2: load r1 = Flag L1:store flag = NEW
L2:load r1 = data
If both the values of data and flag are in sb and have not yet been synchronized to the L2 cache, then core0 and core1 will get initialized 0 when executing the S2 and L2 instructions. This is store-load out of order. The CPU provides instructions to control how this data is synchronized to other cores.
Partial Storage Sequencing (PSO)
TSO brings a lot of performance improvement under the sb structure, but there is still room for further improvement. On top of TSO, continue to relax memory access restrictions, allowing the CPU to process instructions in sbs in non-FIFOs. The CPU only guarantees that address-related instructions are processed in the form of FIFOs in sb, while others can be executed out of order, so it is called partial storage ordering.
Core 0 Core 1
S1: Store data = New;
S2: Store flag = SET; L1: Load r1 = flag;
B1: if(r1≠SET) goto L1;
L2: Load r2 = data;
S1 and S2 above are address-independent store instructions that the CPU pushes into sb when executed. If the flag exists in core0’s cache at this point, the CPU will first execute S2’s store, and then wait for the data cache to be cached in core1 before executing the store data = NEW directive.
The possible execution order is: S2→L1→L2→S1, so that before core0 sets data to NEW, core1 has finished executing, and the final result of r2 is 0, not the NEW we expect, so PSO brings store-store out-of-order.
Relaxed Storage Model (RMO)
In order to squeeze more performance, chip designers have further relaxed the memory consistency model on the basis of PSO, not only allowing store-load, store-store out-of-order. Further run load-load, load-store out of order, as long as it is an address-independent instruction, you can disrupt all load/store orders when reading and writing to the memory.
Core 0 Core 1
S1: Store data = New;
S2: Store flag = SET; L1: Load r1 = flag;
B1: if(r1≠SET) goto L1;
L2: Load r2 = data;
Or the above example, in the PSO S2 may be executed before S1, and because L1 and L2 itself are also address-independent, so load-load can also be out of order, so that even if core0 does not appear store-store out-of-order problem, core 1 itself load-load disorder will lead to r2 to 0.
The above 4 memory models, introduced to squeeze out the performance of the CPU, are not a problem in single-core mode, but the CPU and the compiler are not aware of the existence of multithreads, so this will cause multithreaded memory consistency problems. This leads to the following 6 memory sequences.
C++ memory order
Store and load for the atomic variables in C++ provide the following options:
typedef enum memory_order {
memory_order_relaxed = __mo_relaxed,
memory_order_consume = __mo_consume,
memory_order_acquire = __mo_acquire,
memory_order_release = __mo_release,
memory_order_acq_rel = __mo_acq_rel,
memory_order_seq_cst = __mo_seq_cst,
} memory_order;
The memory order model in the 6 above is defined. It mainly intervenes in the rearrangement intervention on the assembly and the disorderly order on the hardware, and the visibility of the execution results in multiple cores.
memory_order_seq_cst: The underlying layer is required to provide a sequential consistency (SC) model, in which there is no rearrangement. On the underlying implementation, if the underlying architecture of the program runs is a non-memory-strong consistency model, it uses the memory barrier operation provided by the CPU to ensure consistency. In software, code is required to compile without any rearrangement.
memory_order_release/acquire/consume: These are all stores that can allow CPUs or compilers to do certain instruction out-of-order rearrangement, but when it comes to TSO, the memory model of PSO may lead to store-load, store-store problems, and when it comes to multi-core interaction, you need to manually use release, acquire to avoid such problems. It specifically solves the out-of-order that may occur in specific code, rather than requiring it to be rearranged.
memory_order_relaxed: Provides a loose consistency model that allows CPUs and compilers to load 4 kinds according to their own support situation. Store combinations are arbitrarily rearranged. But this can easily lead to problems, generally improving performance when the code is not out-of-order or has no multi-core interactions.
memory_order_seq_cst: This is the default configuration, which means that all the statements that precede this statement cannot be put to the back, and all the statements that follow cannot be put in front. (not only read-write-related operations)
memory_order_acquire: Requires that all subsequent read memory not be placed before this sentence.
memory_order_release: Any write memory operations that are required before this sentence cannot be placed after this sentence.
memory_order_acq_rel: It can be said that the read memory cannot be placed before this sentence, and the write memory cannot be placed after this sentence.
memory_order_consume: It is required that the subsequent readings and writes that depend on this entire statement cannot be out of order.
————————————————
版权声明:本文为CSDN博主「Chris_zhangrx」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Chris_zhangrx/article/details/126927142