
1. Project background
Online shopping has become an important part of people’s life. People browse products and shop on the e-commerce platform, which generates a large amount of user behavior data, and user comment data on products is of great significance to merchants. Making good use of these fragmented and unstructured data will be beneficial to the sustainable development of enterprises on the e-commerce platform. At the same time, analyzing this part of data and optimizing existing products based on review data is also an important role of big data in business operations. practical application.
Analyzing the product: Shaoyin AfterShokz Aeropex AS800 Bone Conduction Bluetooth Headphones Sports Wireless Ear Bone Conduction Headphones Running Cycling Tour de France Special Edition (Aeropex AS800 is a new product of AfterShokz Shaoyin’s Internet celebrity, many runners at home and abroad are using it, on Instagram Also has a lot of heat.)
Analysis Platform: JD.com
Amount of data acquisition: Since JD.com only displays the first 100 pages of data, the latest comment data and negative review data of the first 100 pages are captured as analysis objects
Main tools used: python –jupyter notebook, Alibaba Cloud database, Navicat Premium (My SQL)
2. Project objectives
With the rapid development of electronic information technology in today’s era, online shopping has become popular in millions of households, bringing huge opportunities to the development of the e-commerce industry. At the same time, this demand has also promoted the rise of more e-commerce companies, triggering fierce competition. In the context of this fierce competition, in addition to improving product quality and lowering prices, it is becoming more and more necessary for e-commerce companies to understand more about the voices of consumers. Among them, a very important way is to analyze the internal information of consumers’ comment text data.
The review information contains consumers’ feelings about the characteristics of the product, reflecting people’s attitudes, positions and opinions, and has very valuable research value. For enterprises, analyzing review data can better understand customers’ preferences, so as to target To improve the quality of service and products and increase their own competitiveness, users themselves can provide more references for shopping decisions. This analysis mainly aims to achieve the following goals:
Sentiment Analysis of AfterShokz Aeropex AS800 Bone Conduction Bluetooth Headphones Reviews on JD.com
Mining information such as user needs, opinions, purchase reasons, and product advantages and disadvantages from review texts
Give suggestions for product improvement based on model results
3. Analysis method and process
The main analysis steps are as follows:
Use python to crawl the comment information of Shaoyin AfterShokz Aeropex AS800 bone conduction Bluetooth headset in Jingdong Mall
Use python to perform data cleaning, data segmentation, and stop word filtering on the crawled data
Sentiment analysis is performed on the processed data, and the comment text is divided into positive comment data (good comments) and negative comment data (bad comments) according to the emotional tendency
Perform LDA topic analysis on positive and negative comment data to extract valuable content

4. Data cleaning
data capture
The main goal of this article is to analyze the data. Data capture is time-sensitive. The capture method will not be described here. If you don’t understand it, you can see Python crawler – the realization of the whole process from capturing data to visualization
Comment deduplication
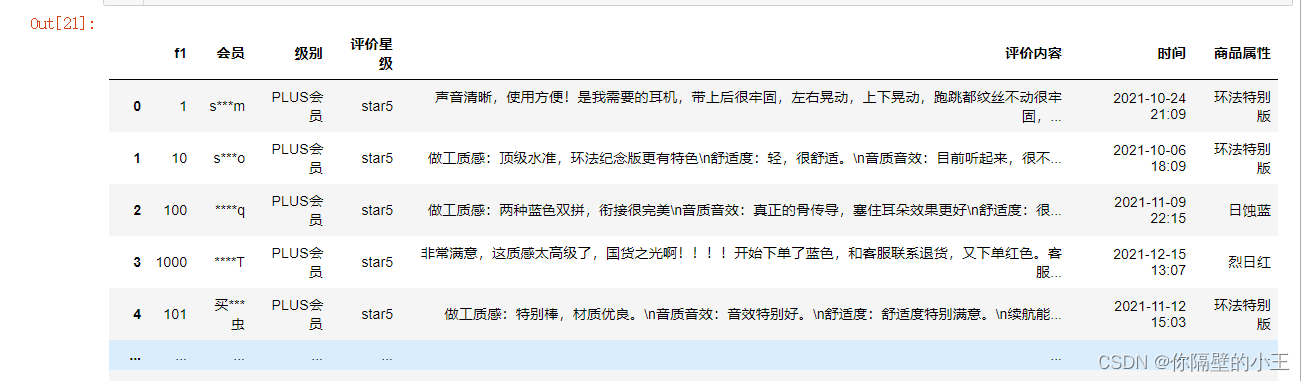
Take out the data from the database, you can see a total of 1260 comment data, divided into 8 columns
#导包
import pandas as pd
import numpy as np
import pymysql
import matplotlib.pyplot as plt
import re
import jieba.posseg as psg
db_info={
‘host’:”***”,
‘user’:”***”,
‘passwd’:’***’,
‘database’:’cx’,# 这里说明我要连接哪个库
‘charset’:’utf8′
}
conn = pymysql.connect(**db_info)
cursor = conn.cursor()
sql = ‘select * from jdsppl’
result = pd.read_sql(sql,conn)
result
result.shape
Some e-commerce platforms will give default evaluations to customers who have not completed order evaluations for a long time. This type of data has no analytical value, but the data crawled this time comes from JD. In order to help small data, there is no such situation in the data crawled this time. At the same time, if there are exactly the same comments in the comments of a product, once or twice or more, then this situation The data below must be meaningless problem data. This kind of comment data only thinks that its first item, that is, it has a certain value when it first appears. In the comments, there will be some comments with a high degree of similarity, but not exactly the same, and there are obvious differences in individual words. In this case, it is incorrect and inappropriate to delete all of them. You can only delete the repeated parts and keep the useful ones. Text comment information, leaving more useful corpus.
reviews = reviews[[‘content’, ‘content_type’]].drop_duplicates()
content = reviews[‘content’]
reviews

It can be seen that 17 duplicate data have been deleted
Through manual observation of the data, it is found that there are many numbers and letters mixed in the comments. For the mining goal of this case, this kind of data itself is not of substantial help. In addition, since the comment text data is mainly evaluated around the AfterShokz Aeropex AS800 bone conduction Bluetooth headset in Jingdong Mall, the frequency of words such as “Jingdong”, “Jingdong Mall”, “Shaoyin”, “earphone” and “Bluetooth headset” appears It is very large, but it has no effect on the analysis target, so these words can be removed before word segmentation to clean the data
# 去除去除英文、数字等
# 由于评论中不重要词语
strinfo = re.compile(‘[0-9a-zA-Z]|京东|京东商城|韶音|耳机|蓝牙耳机|’)
content=result[‘评价内容’]
content = content.apply(lambda x: strinfo.sub(”, x))
content

field has been removed
Participle
Word segmentation is the basic link of text information processing, which is the process of dividing a sequence of words into individual words. The basic unit of Chinese is the character, which can be composed of words, words can be composed of sentences, and some sentences can be composed of paragraphs, sections, chapters, and articles. It can be seen that if a Chinese corpus needs to be processed, it is a very basic and important task to correctly identify words from it. However, Chinese uses characters as the basic writing unit, and there is no obvious distinguishing mark between words.
When using the dictionary-based Chinese word segmentation method for Chinese information processing, the processing of unregistered words has to be considered. Unregistered words refer to names of people, places, institutions, translated names and new words that have not been registered in the dictionary. When using the matching method to segment words, since these words are not registered in the dictionary, it will cause difficulties in automatically segmenting words. Common unregistered words include named entities, such as “Zhang San”, “Beijing”, “Lenovo Group”, “Sakai Noriko”, etc.; technical terms, such as “Bayesian algorithm”, “modality”, “World Wide Web”; new words, such as ” Karaoke”, “Beautiful Knife”, “Chew Old People” and so on. In addition, Chinese word segmentation still has the problem of segmentation ambiguity. For example, the sentence “when combined into molecules” can have the following segmentation methods: “when/combined/component/sub-time” “when/combined/cheng/molecule/time”” When/joining/synthesizing/molecule/when”, “when/joining/synthesizing/molecule/molecule” and so on. It can be said that the key issues of Chinese word segmentation are resolution of ambiguity and recognition of unregistered words. The most commonly used work package for word segmentation is jieba word segmentation package, jieba word segmentation is a word segmentation open source library written in Python, which is specially used for Chinese word segmentation.
stop words
Stop words (Stop Words), the dictionary translates as “virtual words in computer retrieval, non-retrieval words”. In SEO search engines, in order to save storage space and improve search efficiency, search engines will automatically ignore certain words or words when indexing pages or processing search requests. These words or words are called stop words. Generally speaking, stop words can be roughly divided into two categories, one is words that are used too widely and frequently, such as i, is in English, “I” and “you” in Chinese, etc., and the other is words that appear frequently High, but meaningless words, such words generally include modal particles, adverbs, prepositions, conjunctions, etc., which are meaningless in themselves. After word segmentation, the comment is converted from a string into multiple texts or a string of words, used to determine whether a word in a comment is a stop word.
# 分词
worker = lambda s: [(x.word, x.flag) for x in psg.cut(s)] # 自定义简单分词函数
seg_word = content.apply(worker)
# 删除标点符号
result = result[result[‘nature’] != ‘x’] # x表示标点符号
# 构造各词在对应评论的位置列
n_word = list(result.groupby(by = [‘index_content’])[‘index_content’].count())
index_word = [list(np.arange(0, y)) for y in n_word]
index_word = sum(index_word, []) # 表示词语在改评论的位置
# 合并评论id,评论中词的id,词,词性,评论类型
result[‘index_word’] = index_word
result
Post-processing table style
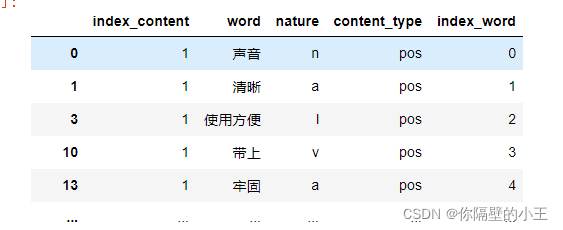
Extract comments containing nouns
Since the goal of this analysis is to analyze the advantages and disadvantages of product features, comments such as “good, very good product” and “very good, continue to support” express the emotional tendency of the product, but in fact it is impossible to base these comments on Which product features are extracted are user-satisfied. Comments are meaningful only when there are clear nouns, such as institutions and other proper nouns, so part-of-speech tagging is required for the words after word segmentation. After that, the comments containing nouns are extracted according to the part of speech. Jieba uses the ICTCLAS tagging method for the part-of-speech tagging of the dictionary. For the part-of-speech tagging, you can see: ICTCLAS Chinese part-of-speech tagging set
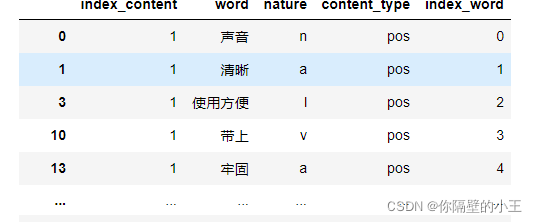
Extract comments containing “n” (noun) in the part of speech,
# 提取含有名词类的评论
ind = result[[‘n’ in x for x in result[‘nature’]]][‘index_content’].unique()
result = result[[x in ind for x in result[‘index_content’]]]
word cloud drawing
After data preprocessing, you can draw a word cloud to view the word segmentation effect. The word cloud will visually highlight the “keywords” that appear frequently in the text. First, you need to count the word frequency of the words, sort the word frequency in descending order, select the first 100 words, use WordCloud in the wordcloud module to draw a word cloud, and check the word segmentation effect (commonly used font codes)
import matplotlib.pyplot as plt
from wordcloud import WordCloud
frequencies = result.groupby(by = [‘word’])[‘word’].count()
frequencies = frequencies.sort_values(ascending = False)
backgroud_Image=plt.imread(‘../data/pl.jpg’)
wordcloud = WordCloud(font_path=”simkai.ttf”,
max_words=100,
background_color=’white’,
mask=backgroud_Image)
my_wordcloud = wordcloud.fit_words(frequencies)
plt.imshow(my_wordcloud)
plt.axis(‘off’)
plt.show()

From the generated word cloud, it can be preliminarily judged that users are more concerned about keywords such as sound quality, texture, battery life, and comfort
5. Data analysis
Comment data sentiment analysis
match sentiment words
Emotional orientation is also known as emotional polarity. In a product review, it can be understood as whether the user’s attitude towards the product is support, opposition or neutral, that is, generally referred to as positive emotion, negative emotion, and neutral emotion. To analyze the emotional tendency of comments, we must first match the emotional words, using the “Chinese Positive Evaluation” vocabulary, “Chinese Negative Evaluation” and “Chinese Positive Emotion” in the “Sentiment Analysis Word Collection (beta version)” released by HowNet. “Chinese Negative Emotion” vocabulary, etc. Merge the two word lists of “Chinese positive evaluation” and “Chinese positive emotion”, and assign an initial weight of 1 to each word as the positive comment emotional word list. Merge the two word lists of “Chinese negative evaluation” and “Chinese negative emotion”, and give each word an initial weight of -1 as the negative comment emotion word list.
Read the emotional vocabulary of positive and negative comments. The positive words are given an initial weight of 1, and the negative words are given an initial weight of -1. The merge function is used to match the word segmentation results according to the emotional vocabulary of words.
import pandas as pd
import numpy as np
word = pd.read_csv(“../tmp/result.csv”)
# 读入正面、负面情感评价词
pos_comment = pd.read_csv(“../data/正面评价词语(中文).txt”, header=None,sep=”\n”,
encoding = ‘utf-8′, engine=’python’)
neg_comment = pd.read_csv(“../data/负面评价词语(中文).txt”, header=None,sep=”\n”,
encoding = ‘utf-8′, engine=’python’)
pos_emotion = pd.read_csv(“../data/正面情感词语(中文).txt”, header=None,sep=”\n”,
encoding = ‘utf-8′, engine=’python’)
neg_emotion = pd.read_csv(“../data/负面情感词语(中文).txt”, header=None,sep=”\n”,
encoding = ‘utf-8′, engine=’python’)
# 将分词结果与正负面情感词表合并,定位情感词
data_posneg = posneg.merge(word, left_on = ‘word’, right_on = ‘word’,
how = ‘right’)
data_posneg = data_posneg.sort_values(by = [‘index_content’,’index_word’])
Modify emotional tendencies
The correction of emotional tendency mainly judges whether the emotional value is correct or not based on whether there are negative words in the two positions in front of the emotional word. Because there are multiple negative phenomena in Chinese, that is, when the negative word appears an odd number of times, it means negative meaning; When a word appears an even number of times, it means affirmative. According to the Chinese custom, search for the first two words of each emotional word, and if there are odd negative words, adjust to the opposite emotional polarity.
# 根据情感词前时候有否定词或双层否定词对情感值进行修正
# 载入否定词表
notdict = pd.read_csv(“../data/not.csv”)
# 去除情感值为0的评论
emotional_value = emotional_value[emotional_value[‘amend_weight’] != 0]
Use the WordCloud function under the wordcloud package to draw word clouds for positive and negative comments to see the effect of sentiment analysis.
# 给情感值大于0的赋予评论类型(content_type)为pos,小于0的为neg
emotional_value[‘a_type’] = ”
emotional_value[‘a_type’][emotional_value[‘amend_weight’] > 0] = ‘pos’
emotional_value[‘a_type’][emotional_value[‘amend_weight’] < 0] = ‘neg’
# 将结果写出,每条评论作为一行
posdata.to_csv(“../tmp/posdata.csv”, index = False, encoding = ‘utf-8’)
negdata.to_csv(“../tmp/negdata.csv”, index = False, encoding = ‘utf-8’)

It can be seen that in the word cloud graph of positive emotional comments, it can be found that words such as “good”, “like”, “satisfied”, and “comfortable” appear frequently, and there are no words with negative emotions. From the negative emotional comments, it can be found that the frequency of words such as “workmanship”, “customer service” and “poor” is relatively high, and no words mixed with positive emotions are found. Therefore, it is effective to analyze the emotional level of the text through the positive vocabulary list .
LDA model for topic analysis
A topic model is a statistical model used in fields such as natural language processing to discover abstract topics in a series of documents. The traditional method of judging the similarity of two documents is by looking at the number of words that appear together in the two documents, such as TF (term frequency), TF-IDF (term frequency-inverse document frequency), etc. This method does not consider the semantic association behind the text , for example, there are few or even no words that appear in two documents, but the two documents are similar, so when judging the similarity of documents, it is necessary to use the topic model for semantic analysis and judge the similarity of documents. If a document has multiple topics, some specific words that can represent different topics will appear repeatedly. At this time, using the topic model, it is possible to discover the rules of words used in the text and link texts with similar rules together. to find useful information in unstructured text sets.
LDA topic model: potential Dirichlet allocation, that is, LDA model (Latent Dirichlet Allocation, LDA) is a generative topic model generation model proposed by Blei et al. in 2003, that is, every word in each document is considered to be passed “A certain topic is selected with a certain probability, and a certain word is selected with a certain probability from this topic”. The LDA model is also known as a 3-layer Bayesian probability model, which includes a document (d), topic (z), and word (w) 3-layer structure, which can effectively model text, and the traditional space vector model (VSM) In contrast, the probability information is increased. Through the LDA topic model, it is possible to mine the potential topics in the data set, and then analyze the focus of the data set and its related feature words.
The LDA topic model is an unsupervised model. It only needs to provide training documents, and various probabilities can be automatically trained without any manual labeling process, which saves a lot of manpower and time. It has a wide range of applications in text clustering, topic analysis, similarity calculation, etc. Compared with other topic models, it introduces Dirichlet prior knowledge. Therefore, the generalization ability of the model is strong, and it is not easy to appear overfitting phenomenon. To establish the LDA topic model, we must first establish a dictionary and corpus
import pandas as pd
import numpy as np
import re
import itertools
import matplotlib.pyplot as plt
# 载入情感分析后的数据
posdata = pd.read_csv(“../data/posdata.csv”, encoding = ‘utf-8’)
negdata = pd.read_csv(“../data/negdata.csv”, encoding = ‘utf-8’)
from gensim import corpora, models
# 建立词典
pos_dict = corpora.Dictionary([[i] for i in posdata[‘word’]]) # 正面
neg_dict = corpora.Dictionary([[i] for i in negdata[‘word’]]) # 负面
# 建立语料库
pos_corpus = [pos_dict.doc2bow(j) for j in [[i] for i in posdata[‘word’]]] # 正面
neg_corpus = [neg_dict.doc2bow(j) for j in [[i] for i in negdata[‘word’]]] # 负面
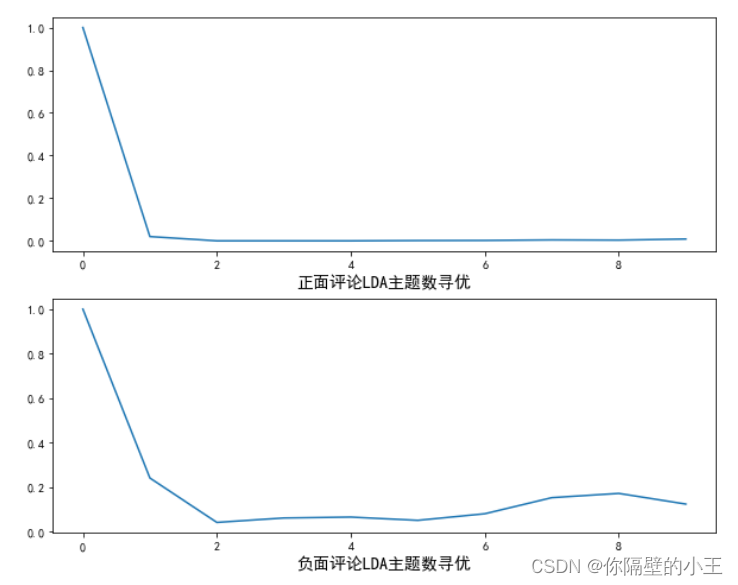
Finding the Optimal Number of Topics
Adaptive optimal LDA model selection method based on similarity, determine the number of topics and perform topic analysis. Experiments show that the method can find the optimal topic structure with relatively few iterations without manually adjusting the number of topics. Specific steps are as follows:
1) Take the initial topic number k value to get the initial model, and calculate the similarity (average cosine distance) between the topics.
2) Increase or decrease the k value, retrain the model, and calculate the similarity between the topics again.
3) Repeat step 2 until the optimal k value is obtained.
The cosine similarity between topics is used to measure the similarity between topics. Starting from word frequency, calculate their similarity, the more similar the words, the more similar the content.
# 计算主题平均余弦相似度
pos_k = lda_k(pos_corpus, pos_dict)
neg_k = lda_k(neg_corpus, neg_dict)
# 绘制主题平均余弦相似度图形
from matplotlib.font_manager import FontProperties
font = FontProperties(size=14)
#解决中文显示问题
plt.rcParams[‘font.sans-serif’]=[‘SimHei’]
plt.rcParams[‘axes.unicode_minus’] = False
fig = plt.figure(figsize=(10,8))
ax1 = fig.add_subplot(211)
ax1.plot(pos_k)
ax1.set_xlabel(‘正面评论LDA主题数寻优’, fontproperties=font)
ax2 = fig.add_subplot(212)
ax2.plot(neg_k)
ax2.set_xlabel(‘负面评论LDA主题数寻优’, fontproperties=font)
Evaluate thematic analysis results
According to the optimization results of the number of topics, the Gensim module of Python is used to construct the LDA topic model for the positive comment data and the negative comment data respectively, and the number of topics is selected as 2. After LDA topic analysis, 10 most likely topics are generated under each topic. Words and their corresponding probabilities
# LDA主题分析
pos_lda = models.LdaModel(pos_corpus, num_topics = 2, id2word = pos_dict)
neg_lda = models.LdaModel(neg_corpus, num_topics = 2, id2word = neg_dict)
pos_lda.print_topics(num_words = 10)
neg_lda.print_topics(num_words = 10)

tidy:
Positive comments on potential topics:
| 1 | 2 | 1 | 2 |
| 音质 | 耳朵 | 感觉 | 传到 |
| 喜欢 | 不错 | 骨 | 运动 |
| 做工 | 质感 | 舒适度 | 音效 |
| 满意 | 听 | 舒服 | 续航 |
| 耳朵 | 跑步 | 很快 | 值得 |
 Potential topics for negative reviews:
Potential topics for negative reviews:
| 1 | 2 | 1 | 2 |
| 客服 | 耳朵 | 几天 | 差 |
| 传导 | 骨 | 新 | 赠品 |
| 音质 | 快递 | 理解 | 做工 |
| 坏 | 不好 | 产品 | 找 |
| 声音 | 太 | 回来 | 中 |
6. Conclusion analysis
Based on the above analysis of the topic and its high-frequency feature words, it can be concluded that the advantages of Shaoyin AfterShokz Aeropex AS800 are mainly concentrated in two categories, the first is the quality and comfort of the earphone itself, the performance of the product itself, and the second is the product. Positioning means functionality. Shaoyin AfterShokz Aeropex AS800 focuses on sports earphones. Judging from the emotional words of user evaluations, the promotion of Shaoyin AfterShokz Aeropex AS800 is in place. Relatively speaking, users complain about Shaoyin AfterShokz Aeropex AS800 The main points are poor after-sales service and low quality gifts and logistics speed.
Therefore, the reasons for the user’s purchase can be summarized as the following aspects: clear product positioning, reliable performance, and high cost performance
According to the LDA topic model analysis of the user evaluation of Shaoyin AfterShokz Aeropex AS800 earphones on the JD platform, the following two suggestions are put forward for the Midea brand:
1. On the basis of maintaining the quality and performance of the main product, further strengthen the gifts and sound quality;
2. Continue to maintain the advantages of clear product positioning and fixed customer groups;
3. Improve the overall quality of customer service personnel, improve service quality, and focus on after-sales service. Establish clear rules for after-sales service, do a good job in the whole process of product service, and increase the core competitiveness of products.