
First, understand the disk
The disk is the main storage medium of the computer, it can store a large amount of binary data, and the data will not be lost even after the power is turned off. Next, let’s take a brief look at the structure of the disk?
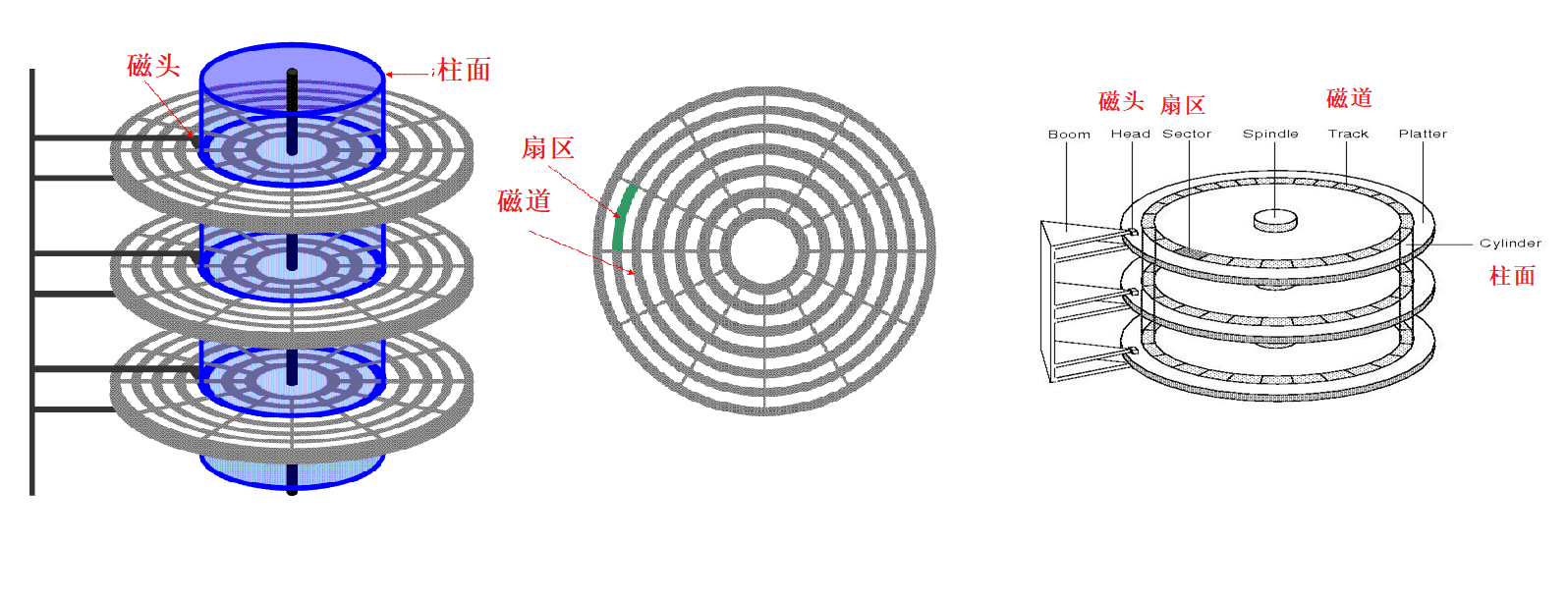
1. The physical structure of the disk
The disk is a peripheral and the only mechanism in our computer (the mechanism is relatively slow)
The platters/sides of a disk are like a CD (on which data is stored) and have both sides. And like a knife is the magnetic head (each side has a magnetic head), the magnetic head and the disk surface are not in contact, and the disk must be prevented from shaking. There is a motor in the middle. Once the disk is powered on, the disk rotates and the head swings. The motor can control the swing of the head and the rotation of the disk. The corresponding disk also has its own hardware circuit. Through the hardware circuit + servo system, binary instructions are sent to the disk to allow the disk to locate and address a certain area.

2. Disk storage structure
When addressing the disk, its basic unit is neither bit nor byte, but sector.
Sector size: 512 bytes, 512 bytes is a hardware requirement, the size of the outer track and the inner track are the same, but the density is different. The bits closer to the center of the circle are bigger, and the bits outside are smaller.
Sector positioning on a single side: By confirming the track, it is finally determined which sector of the corresponding track it is in. Confirm the track: each track has its own number, the perimeter of the track is different, but the storage size is the same, because the sector size is the same, the number of sectors in a track is also fixed, so the sectors of each track also have numbers site. So it can be found by positioning on a certain track.
The addressing method of the mechanical hard disk: the platter rotates continuously and the magnetic head oscillates continuously, which is to confirm which track it is on, and how to confirm which sector it is on? The platter is also spinning to allow the heads to position the sectors.
Cylinder: Press a series of concentric magnetic tracks together, and look at it as a whole macroscopically. When generally positioning: head, cylinder, sector ==== (head, track, sector), these two are equivalent. The position where the cylinder is equivalent to the head pointing together is the boundary position of the cylinder.
Locate any sector in the disk: first locate which track (which cylinder), the track is determined, all the heads advance and retreat together, and the head does not move at this time, and then locate the head (locate the disk surface), and finally locate which sector district.
Summary: To locate any sector in the disk, the hardware-level positioning method (CHS positioning method) adopted: Cylinder——Head——Sector
3. The logical structure of the disk
Similar to a magnetic tape, it is circular when rolled up, and linear when pulled apart. So we can imagine the disk platter as a linear structure. From the perspective of OS, the disk is considered to have a linear structure. To access a certain sector, you only need to locate the array subscript, that is to say, if you know the subscript of this sector, you can locate a sector. Inside the operating system, we call this address an LBA (Logic Block Address) address! To write to the physical disk, we need to convert the LBA address into the three-dimensional address CHS address of the corresponding disk. In summary, the OS address is the LBA address, and the corresponding disk is the CHS address.
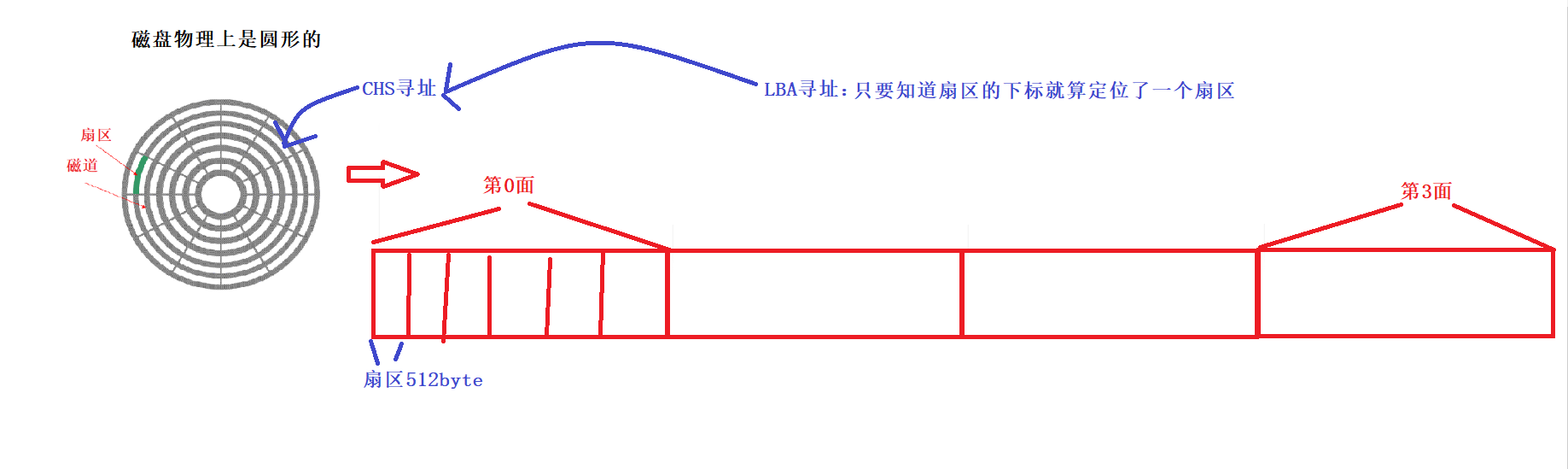
The OS needs to carry out logical abstraction instead of directly using CHS: 1. It is easy to manage, manage arrays and manage three-dimensional structures, and arrays are better managed; 2. Don’t want OS code and hardware to be strongly coupled! For example, if the basic size of the disk changes, the source code of the OS must change accordingly.
2. File system and inode
How files are stored on disk: files are stored on disk, and the logical structure is a linear structure. The disk space is very large. Although the basic unit of the corresponding disk access is 512 bytes, it is still very small. The file system in the OS will customize the reading of multiple sectors, with 1KB, 2KB, and 4KB as the basic unit , so even if 1bit is read/modified, 4KB must be loaded into memory, read or modified, and then written back to disk. We use the idea of divide and conquer to manage disk space and partition: large disk space -> small space, big things are reduced, and different file systems are written to each partition.
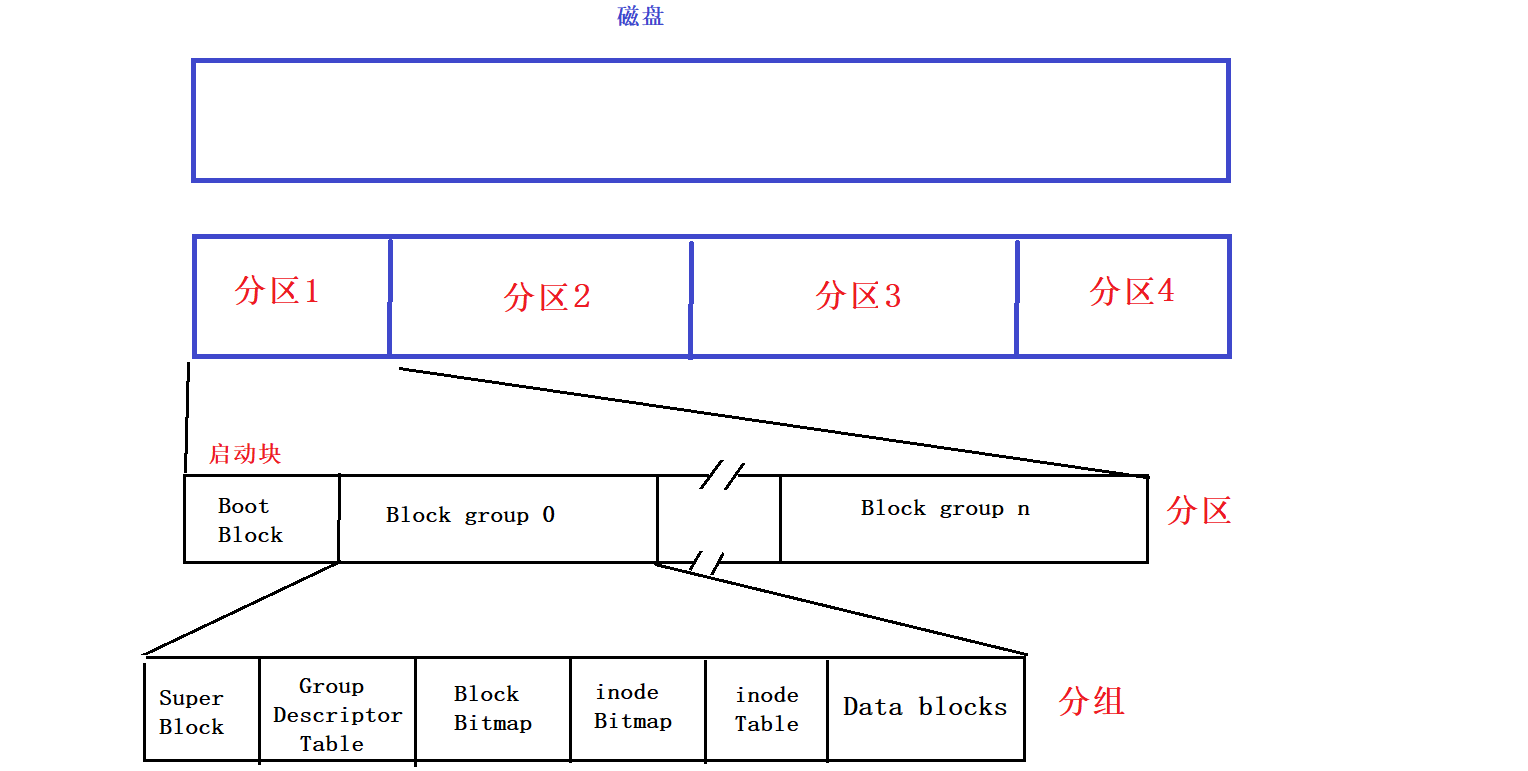
Boot Block is a boot block, which exists at the beginning of each partition, and backup files are related to boot.
Continue to group the remaining space, Block group 0…Block group n. Manage Block group0 well, and others can also manage well, so we only need to understand Block group 0:
Super Block: It saves the information of the entire file system. Why does the Super Block not exist at the beginning of each partition like the Boot Block? Super Blocks stored in different groups means backup. If a Super Block is damaged, the Super Blocks of other groups can be copied.
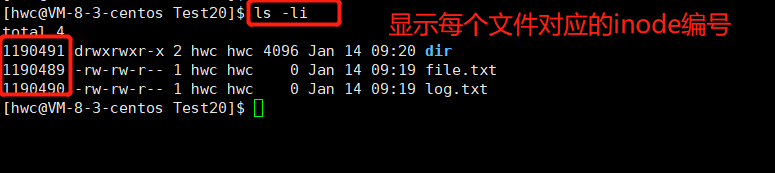
Linux files = content + attributes, and Linux file contents are attributes that are stored in batches. It is the inode that saves the file attributes, and the size of the inode block is fixed at 128 bytes. A file, an inode, contains almost all attributes of the file, and the file name is not stored in the inode. The content of the file is stored in the data block, and the content of different files is different, and the size changes with the change of the application type. In order to distinguish each other, each inode has its own ID. Here we use the command ls -li to view the inode number:
inode table: saves all available (already used + unused) inodes in the group. As mentioned earlier, generally speaking, a file corresponds to an inode
Data blocks: save the data blocks of all files in the group
inode Bitmap: The bitmap structure corresponding to the inode, and the usage of the inode is counted. The position of the bit in the bitmap corresponds to the position of the inode corresponding to the current file. If the bit is 1, it means that the inode is occupied, otherwise it means that it is available.
Block Bitmap: The bitmap structure corresponding to the data block, the bit position in the bitmap and the data block position corresponding to the current data block are one-to-one correspondence positions
GDT (group descriptor table): Block group description table, which corresponds to the macro attribute information of the group, how many have been used, how many inodes are there, how many have been occupied, and how many are left.
When searching for files, the inode number is used uniformly.
The content is placed in data blocks, the attributes are in the inode table, and an array is stored inside the inode, which stores the number of the corresponding block, and the two are connected:
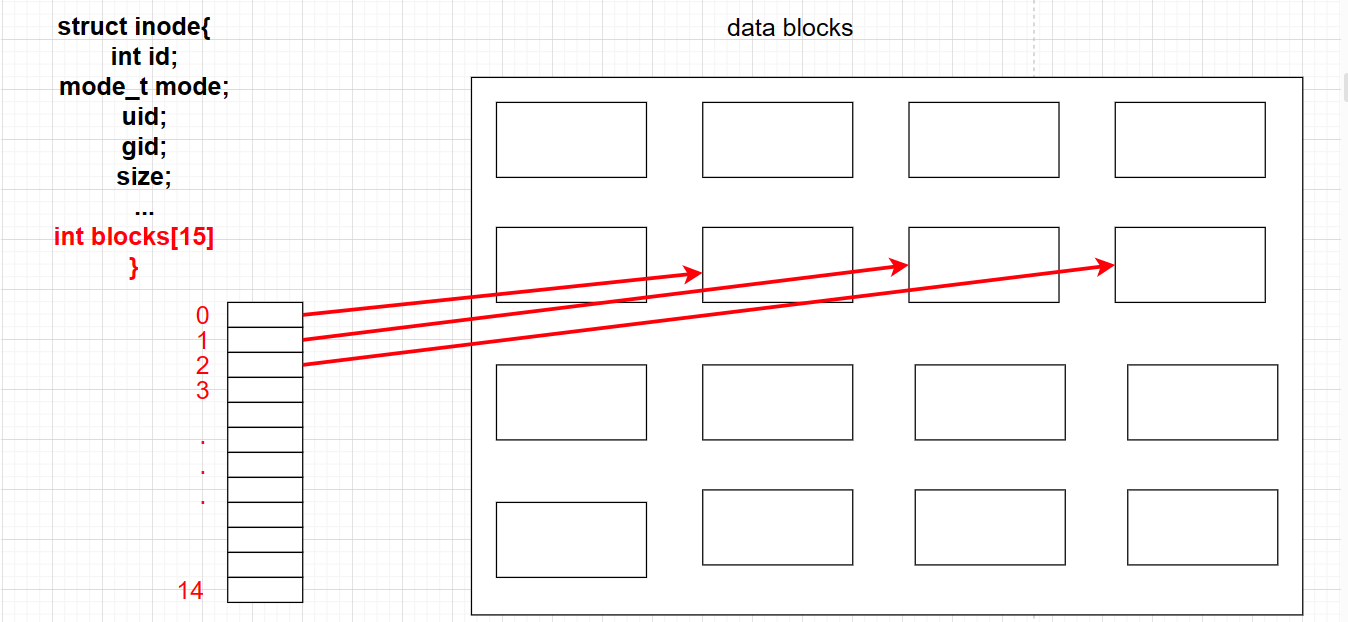
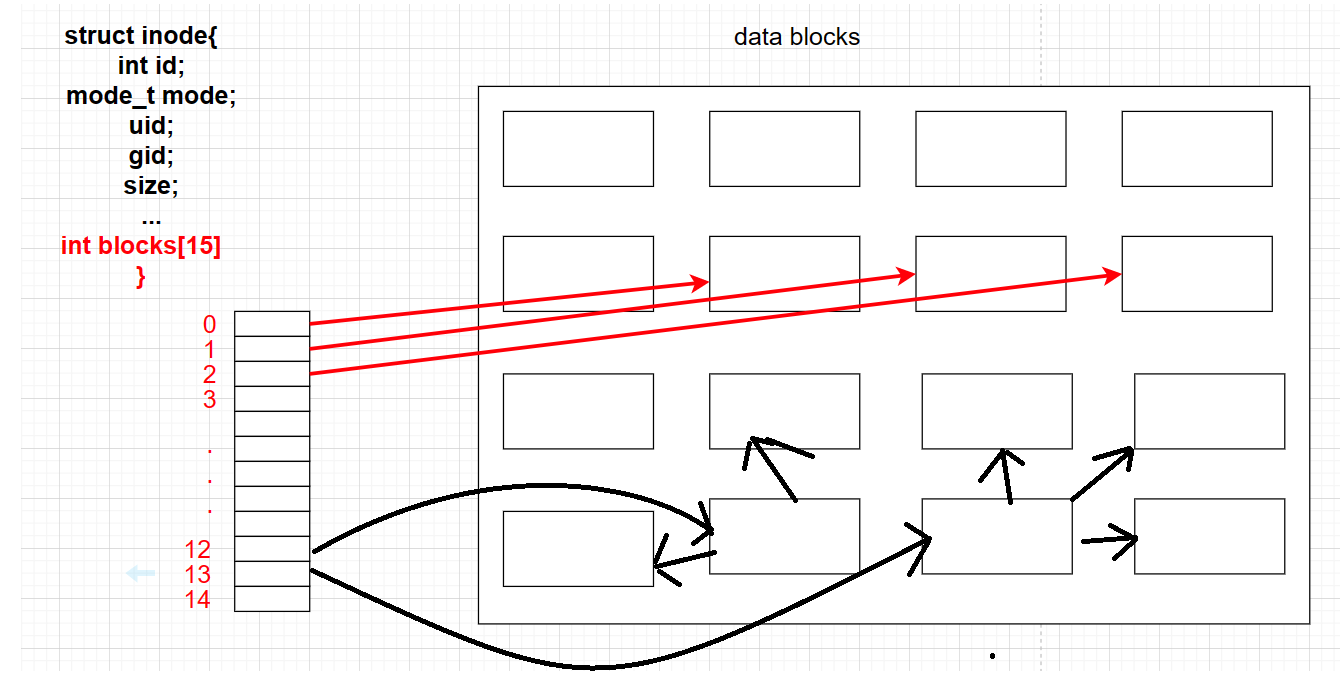
But what if the file is particularly large? Not all data blocks can only store file data, and can also store block numbers of other blocks, so they eventually point to more blocks for storage
Create a file: set the bit of the bitmap from 0 to 1, find its inode table, fill in the attributes, write the data of the file into the block, establish a mapping relationship between the inode and the block, and finally return the inode number, the creation is successful
Find a file: get the inode, find the inode table, find the corresponding data block according to the inode table, and find all the content plus attributes
Deleting a file: Deleting a file also requires the inode. In fact, when deleting a file, we only need to find the bit of the inode in the inode bitmap, and set the bit from 1 to 0 to delete it.
Therefore, deleting a file does not need to clear the data attribute and content at all, as long as the 1 of the inode bitmap is set to 0, the attribute will be deleted. This file also occupies a data block, and the bit of the block is also set to 0. Therefore, deleting a file can be recovered. Once deleted, the bit is cleared. To recover, you only need to get the number of the inode, and then set the bit in the inode bitmap from 0 to 1, and then go to the mapping table corresponding to the inode table , set 0 to 1 in the block bitmap.
If you delete a file by mistake in Linux, it can still be recovered, but the premise must be that the inode and data block are not occupied, so when you delete a file by mistake, the best way is to do nothing. And when we delete files to the recycle bin in Windows, we just transfer the directory, and deleting in the recycle bin is the real deletion.
But when we search for a file, we don’t use the inode, but the file name?
Any file is in a directory, but these files do not have duplicate file names
A directory is a file with its own inode and corresponding data block. The data block of the directory stores the mapping relationship between the file name and the inode in the current directory, so the inode does not need to save the file name.
So when we add a file in a directory, we must have write permission. When adding a file, we need to write the mapping relationship between the file name and inode in the content of the current directory, so we must have write permission. To list the current files, you must have read permission. When you want to read, you need to find the inode according to the file name and read the attributes of all the files below. What you read is to get the file name and you must access the data block, so you must have read permission.
3. Soft and hard links
1. Soft link
Create a soft link: (file name is not important)
ln -s myfile.txt soft_file.link
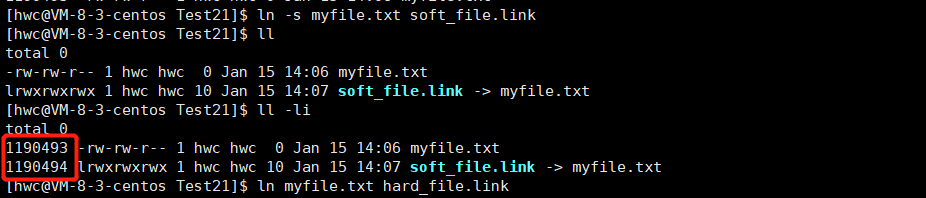
A soft link with its own independent inode is called a soft link, that is, a soft link is an independent file, and an independent file has an independent inode and corresponding file content.
The so-called soft link calibration file is not marked with inode, we delete myfile.txt, and then go to cat soft_file.link:

Therefore, this soft link does not use the inode corresponding to the target file, but uses the file name of the target file. After deleting the file, it cannot be found. The data block of the soft link stores the path of the target file pointed to, so the target file Once deleted, the soft link will become invalid.
Delete soft links: either rm or unlink
unlink soft_file.link
1
Soft links are equivalent to shortcuts. The role of soft links:
When the execution path is very deep and the path is very long, we may forget the path, so we can quickly find it through the soft link without entering a long path every time:
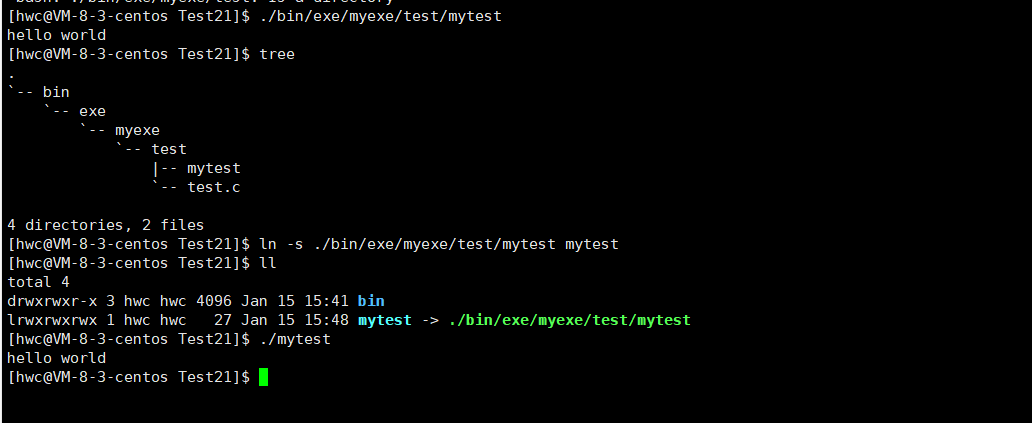
This is equivalent to a Windows shortcut.
2. Hard link
Create hard links:
ln myfile.txt hard_file.link
1
Without s, it is a hard link.
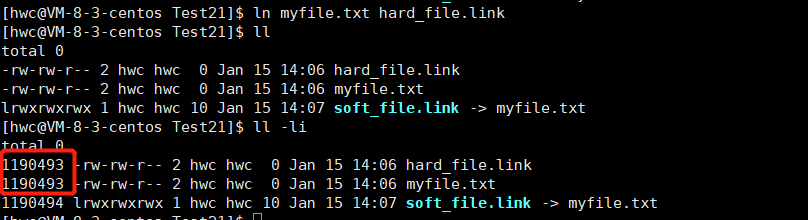
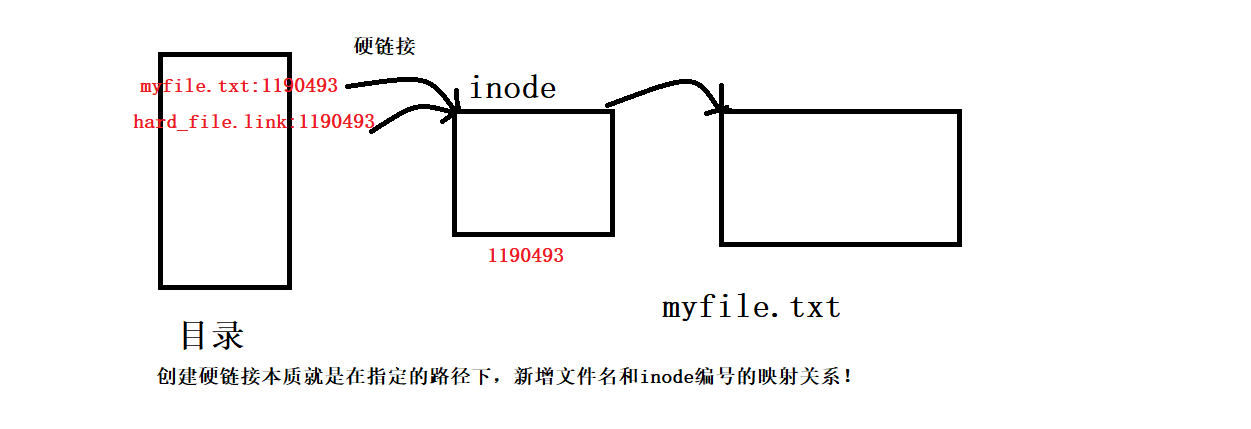
The most important difference between soft and hard links is whether they have independent inodes. Hard links do not have independent inodes, and point to inodes of other files, not independent files. **What is a hard link doing? **When the size and content of one of the files in the hard link changes, the hard link files will change accordingly, so there is no new file at all when the hard link is established, because no independent inode is assigned to the hard link, since it is not created The file does not have its own attribute collection and content collection, but uses other people’s inodes and content. The essence of creating a hard link is to add a mapping relationship between the file name and the inode number under the specified path!
The inode may be pointed to by multiple files, so the inode has a calculator, the reference count of count, and the reference count is called the number of hard links:
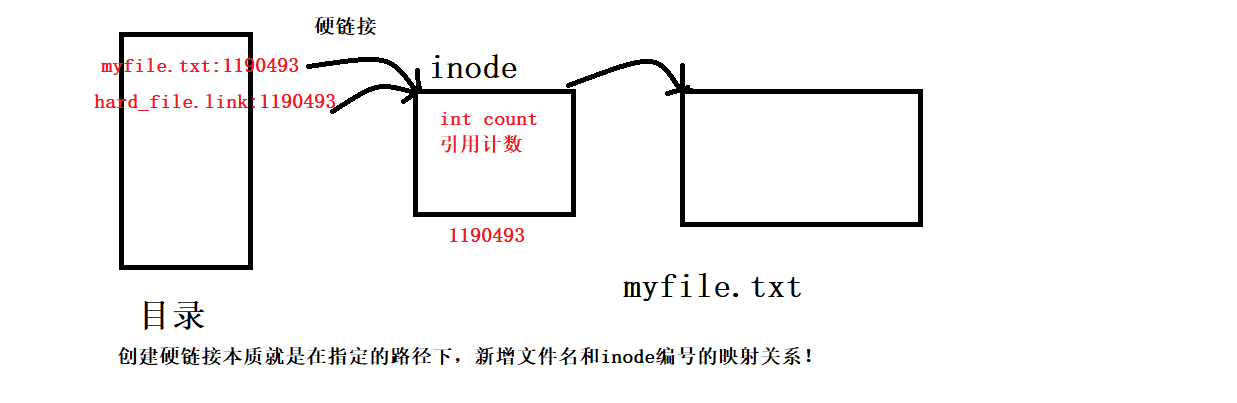
This is why we can see that 1 becomes 2, because with the new file name, the inode is pointed to by two files, and the number of hard links becomes 2:
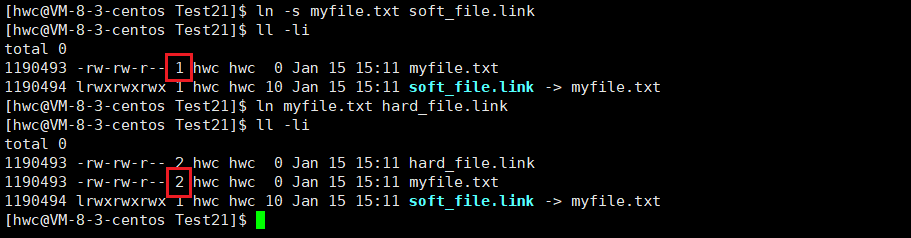
If the hard-linked file is deleted, the original file corresponding to the inode number:

So a file is really deleted: when the number of hard links of a file becomes 0, it is really deleted.
The role of hard links:
Why is the number of hard links 1 when creating an ordinary file?

Because an ordinary file itself has a file name and its own inode, which has a mapping relationship!
Why is the number of hard links 2 when creating a directory?

First of all, the directory and its own inode are a set of mapping relationships. In addition, the second is inside the directory. (. Indicates the current directory, which is also the file name. The inode is the same) and the inode is also a set of mappings, so it is the number of hard links is 2
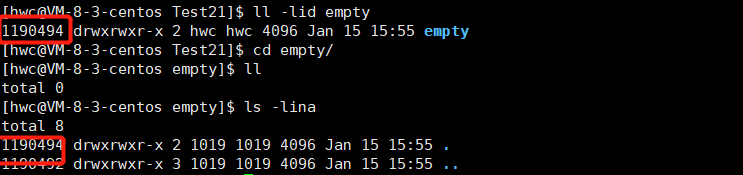
Now create a directory dir under the empty directory, and the number of hard links in the empty directory has changed to 3:

Because at this time the … file of dir points to the empty directory of the superior, so the number of hard links is 3
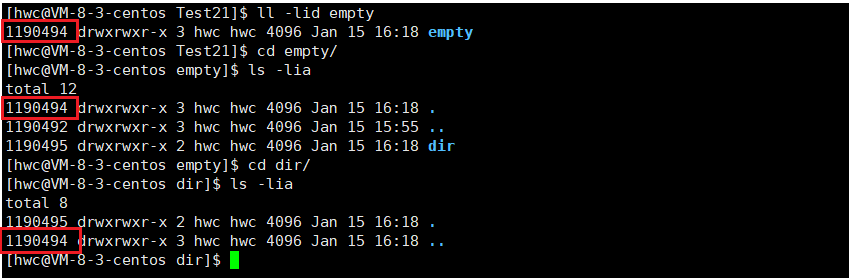
Four. Summary
We have a general understanding of the physical structure, storage structure, and logical structure of the disk; and then the understanding of the file system and inode.
Finally, there are soft and hard links. The essential difference between soft and hard links is whether there is an independent inode.