1. Overview
Bidirectional Encoder Representation from Transformers(BERT [1], the Encoder representation of the bidirectional Transformer, is a context-based pre-trained model proposed in 2018 that learns the general epimediation form of each word through a large number of corpus, and learns the context-independent semantic vector representation to achieve modeling of polysemantic words. The relationship with the pre-trained language models ELMo[2] and GPT[3] is shown in the following figure: hmi panel module
Embeddings from Language Models(ELMo)[2], Generative Pre-Training(GPT)[3], and Biddirectional Encoder Representation from Transformers (BERT)[1] All three are pre-trained models based on context, and both are two-stage processes, the first of which is to use an unsupervised approach to the language model Pre-training is carried out, and the second stage is Fine-tuning on specific language tasks by means of supervision. The difference is the bidirectional LSTM algorithm used in ELMo; The feature extraction algorithm used in GPT is Transformer[4], and it is a one-way Transformer language model, compared with the LSTM model in ELMo, the Transformer-based model has better feature extraction capabilities; The Transformer-based feature extraction algorithm is also used in BERT, which differs from the GPT:
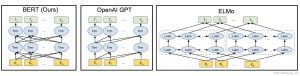
First, the Transformer in BERT is a two-way Transformer model that further improves the extraction capability of features
Second, the Decoder model in Transformer is used in GPT, and the Encoder model in Transformer is used in BERT.
2. Principle of algorithm
2.1. Transformer structure
The network structure of Transformer is shown in the following figure:
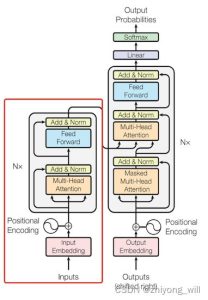
In the Transformer, there are two parts, Encoder and Decoder, in the training of language models, the traditional practices based on RNN and CNN are abandoned, and the Attention-based model is adopted, which can improve the extraction ability of features and facilitate parallel learning. BERT uses the Encoder part of Transformer, as shown in the red box in the image above.
2.2. The Rationale of BERT
BERT is a pre-trained model based on the context, and the training of the BERT model is divided into two steps: first, pre-training; Second, fine-tuning.
In the pre-training phase, the BERT model is pre-trained with a large amount of text, however, the labeled samples are very precious, and in BERT, a large number of unlabeled samples are used to pre-train the BERT model. In the fine-tuning stage, the model structure will be appropriately modified for different downstream tasks, and at the same time, the parameters in the model will be readjusted through samples of specific tasks.
In order for BERT to adapt to more applications, the model uses two tasks of Masked Language Model (MLM) and Next Sentence Prediction (NSP) as pre-trained tasks in the pre-training stage, of which MLM can learn the Embedding of words and NSP can learn the Embedding of sentences. In Transformer, the input adds the word vector to the position vector, while in BERT, in order to be able to adapt to the above two tasks, namely MLM and NSP, The Immuning here contains the sum of the three Embeddings, as shown in the following figure:
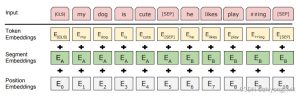
Among them, Token Embeddings is a word vector, the first word is a CLS flag, which can be used for subsequent classification, Segment Embeddings is used to distinguish between the two sentences, which is in the pre-training stage, for the input of NSP tasks, Position Embeddings is a position vector, but unlike in Transformer, like word vectors, it is learned. There are two kinds of markup here, one is, which can be understood as a vector representation of the entire input feature; The other is, used to distinguish between different sentences.[CLS][SEP]
2.2.1. Pre-trained MLM
The principle of masked Language Model is to randomly replace some words with, in the process of training, through contextual information to predict the words to be masked. The following example is given in the document [1]: “my dog is hairy”, where the randomly selected word is “hairy”, the sample is replaced with “my dog is [MASK]”, and the purpose of training is to enable the BERT model to predict that “[MASK]” here is “hairy”. At the same time, the probability of random substitution is[MASK]15 % 15\%15%。 At the same time, for this15 % 15\%15%Of random selection, divided into the following three cases:
Select the word80 % 80\%80%Replace with [MASK], such as: “my dog is [MASK]”
Select the word10 % 10\%10%Random substitution, such as replacing with apple, i.e. “my dog is apple”
Select the word10 % 10\%10%Keep it the same, i.e.: “my dog is hairy”
The purpose of this is to let the model know that the corresponding token of the location can be any word, so that the model is forced to learn more contextual information and does not pay too much attention to the current token.
2.2.2. Pre-trained NSPs
The purpose of Next Sentence Prediction is to make the model understand the relationship between two oranges, the input for training is two sentences, and the BERT model needs to judge whether the latter sentence is the next sentence of the previous sentence. In Input, there are Segment Embeddings, which are different sentences that are marked. When selecting training data, enter sentences A and B, B has a 50% probability of being the next sentence of A, such as:

2.3. BERT’s network structure
According to Transformer’s Encoder structure, for a single Attention process, there is the following BERT structure:
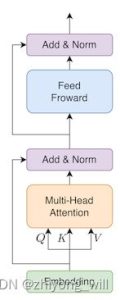
The specific computational logic of Attention can be found in reference [5], which provides a detailed introduction to the basic principles of Transformer. Reference [6] gives the code implementation of BERT, where the code for the transformer section looks like this:
def transformer_model(input_tensor,
attention_mask=None,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
intermediate_act_fn=gelu,
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
initializer_range=0.02,
do_return_all_layers=False):
“””Multi-headed, multi-layer Transformer from “Attention is All You Need”.
This is almost an exact implementation of the original Transformer encoder.
See the original paper:
https://arxiv.org/abs/1706.03762
Also see:
https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/models/transformer.py
Args:
input_tensor: float Tensor of shape [batch_size, seq_length, hidden_size].
attention_mask: (optional) int32 Tensor of shape [batch_size, seq_length,
seq_length], with 1 for positions that can be attended to and 0 in
positions that should not be.
hidden_size: int. Hidden size of the Transformer.
num_hidden_layers: int. Number of layers (blocks) in the Transformer.
num_attention_heads: int. Number of attention heads in the Transformer.
intermediate_size: int. The size of the “intermediate” (a.k.a., feed
forward) layer.
intermediate_act_fn: function. The non-linear activation function to apply
to the output of the intermediate/feed-forward layer.
hidden_dropout_prob: float. Dropout probability for the hidden layers.
attention_probs_dropout_prob: float. Dropout probability of the attention
probabilities.
initializer_range: float. Range of the initializer (stddev of truncated
normal).
do_return_all_layers: Whether to also return all layers or just the final
layer.
Returns:
float Tensor of shape [batch_size, seq_length, hidden_size], the final
hidden layer of the Transformer.
Raises:
ValueError: A Tensor shape or parameter is invalid.
“””
if hidden_size % num_attention_heads != 0:
raise ValueError(
“The hidden size (%d) is not a multiple of the number of attention ”
“heads (%d)” % (hidden_size, num_attention_heads))
attention_head_size = int(hidden_size / num_attention_heads) # self-attention的头
input_shape = get_shape_list(input_tensor, expected_rank=3)
batch_size = input_shape[0] # batch的大小
seq_length = input_shape[1] # 句子长度
input_width = input_shape[2]
# The Transformer performs sum residuals on all layers so the input needs
# to be the same as the hidden size.
if input_width != hidden_size:
raise ValueError(“The width of the input tensor (%d) != hidden size (%d)” %
(input_width, hidden_size))
# We keep the representation as a 2D tensor to avoid re-shaping it back and
# forth from a 3D tensor to a 2D tensor. Re-shapes are normally free on
# the GPU/CPU but may not be free on the TPU, so we want to minimize them to
# help the optimizer.
prev_output = reshape_to_matrix(input_tensor)
all_layer_outputs = []
for layer_idx in range(num_hidden_layers):
with tf.variable_scope(“layer_%d” % layer_idx):
layer_input = prev_output
with tf.variable_scope(“attention”): # attention的计算
attention_heads = []
with tf.variable_scope(“self”):
attention_head = attention_layer(
from_tensor=layer_input,
to_tensor=layer_input,
attention_mask=attention_mask,
num_attention_heads=num_attention_heads,
size_per_head=attention_head_size,
attention_probs_dropout_prob=attention_probs_dropout_prob,
initializer_range=initializer_range,
do_return_2d_tensor=True,
batch_size=batch_size,
from_seq_length=seq_length,
to_seq_length=seq_length)
attention_heads.append(attention_head) # 多头注意力
attention_output = None
if len(attention_heads) == 1:
attention_output = attention_heads[0]
else:
# In the case where we have other sequences, we just concatenate
# them to the self-attention head before the projection.
attention_output = tf.concat(attention_heads, axis=-1) # concat多头的输出
# Run a linear projection of `hidden_size` then add a residual
# with `layer_input`.
with tf.variable_scope(“output”):
attention_output = tf.layers.dense(
attention_output,
hidden_size,
kernel_initializer=create_initializer(initializer_range))
attention_output = dropout(attention_output, hidden_dropout_prob) # dropout
attention_output = layer_norm(attention_output + layer_input) # layer norm
# The activation is only applied to the “intermediate” hidden layer.
with tf.variable_scope(“intermediate”):
intermediate_output = tf.layers.dense(
attention_output,
intermediate_size,
activation=intermediate_act_fn,
kernel_initializer=create_initializer(initializer_range))
# Down-project back to `hidden_size` then add the residual.
with tf.variable_scope(“output”):
layer_output = tf.layers.dense(
intermediate_output,
hidden_size,
kernel_initializer=create_initializer(initializer_range))
layer_output = dropout(layer_output, hidden_dropout_prob)
layer_output = layer_norm(layer_output + attention_output)
prev_output = layer_output
all_layer_outputs.append(layer_output)
if do_return_all_layers:
final_outputs = []
for layer_output in all_layer_outputs:
final_output = reshape_from_matrix(layer_output, input_shape)
final_outputs.append(final_output)
return final_outputs
else:
final_output = reshape_from_matrix(prev_output, input_shape)
return final_output
2.3.1. BERT is a bidirectional transformer
The GPT model uses the Decoder part of the Transformer (with some changes to the original Decoder part), while the BERT uses the Encoder part of the Transformer, and the following figure shows the comparison between the two on a Transformer module:
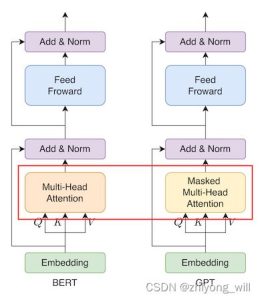
As can be seen from the image above, the only difference is in the Multi-Head Attention section, as shown in the red box in the figure, where Multi-Head Attention is used in BERT and Masked Multi-Head Attention is used in GPT. The Masked Multi-Head Attention is a generative model applied in the Decoder phase, i.e. int ttMoments, according tot − 1 t-1t−1Word prediction at and before the momentt ttMoment of words, fort ttMoments as wellt ttWords after the moment are invisible, so Masked Multi-Head Attention is a one-way model that is not convenient for parallelism.

For Multi-Head Attention, the calculation method is shown in the following figure:
In the process of calculating TheTontion, both the information above and below will be used, but the “it_” in the above figure will be marked with a certain probability. Therefore, the BERT model is a bidirectional language model, and at the same time, the Attention computation in BERT is conducive to parallel computation
2.3.2. Fine Tune
For NLP tasks, there are four main categories:
Sequence annotations, such as Chinese participles, part-of-speech annotations, named entity recognition (features: each word in a sentence requires the model to give a classification category according to the context)
Classification tasks such as text classification, affective computing (feature: overall gives a classification category)
Sentence relationship judgment, such as QA, semantic rewriting (feature: given two sentences, the model determines whether two sentences have some semantic relationship)
Generative tasks such as machine translation, text summarization, writing poems, reading pictures and speaking (feature: after entering the text content, you need to generate another paragraph of text on your own)
Generative tasks are described in detail in Transformer. For the other three types of tasks, a typical scenario is shown in the following figure:
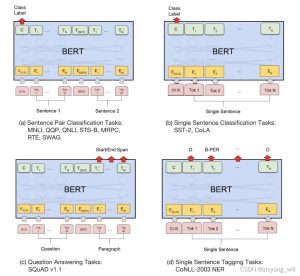
First, the classification task of sentence pairs, that is, the input is two sentences, the input is as shown in the following figure:
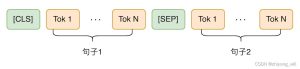
The output is the first implicit layer vector of BERT[CLS]C ∈ R H C\in \mathbb{R}^HC∈R
H
, in the Fine-Tune phase, add a weight matrixIn ∈ R K × H W\in \mathbb{R}^{K\times H}W∈R
K×H
thereintoK KKIs the number of categories that are categorized. The final output probability is finally obtained by the Softmax function.
Second, the classification of individual sentences. Relative to the classification task of sentence pairs, the input is a single sentence, as shown in the following figure:
Its output is the same as the output of the sentence to the classification.
Third, the Q&A task, whose input is like the input of sentence pairs, the difference is that the first sentence is the question and the second sentence is the paragraph.
Fourth, for each word of the tag, its input is like the input of a single sentence, the output is for each token of the implicit layer output of the tag.
3. Summary
The proposed BERT model has greatly improved the effect of NLP pre-training, using Self-Attention as the mining of text features on the basis of the ELMo model, while avoiding the one-way language model in the GPT model and making full use of the context features in the text.