
1. What is an index?
When we want to find a certain knowledge point in a book, we usually don’t traverse page by page, but lock the specific position in the directory. This can save a lot of time, and the directory in the book acts as an index , On the one hand, we can quickly find the content in the book, a typical design idea of changing space for time.
Then converted to the database, the index is a data structure that helps the storage engine to quickly obtain data, vividly said: “The index is the directory of the data”.

2. Index classification
When it comes to indexes, you may think of clustering indexes, primary key indexes, secondary indexes, ordinary indexes, unique indexes, hash indexes, B+ tree indexes, etc. To understand the use and implementation of these indexes, you need to use them according to the index Classify them with the same characteristics.
We can classify indexes according to four angles:
1. According to the data structure: B+ tree index, Hash index, Full-text index.
2. According to physical storage: clustered index (primary key index), secondary index (auxiliary index).
3. According to field characteristics: primary key index, unique index, common index, prefix index.
4. According to the number of fields: single column index, joint index.
This article mainly talks about classifying indexes according to data structure:
Common indexes classified by data structure in MySql include B+ tree index, Hash index, and Full-Test index. The index types supported by each storage engine in the database are not necessarily the same, as shown in the following figure:
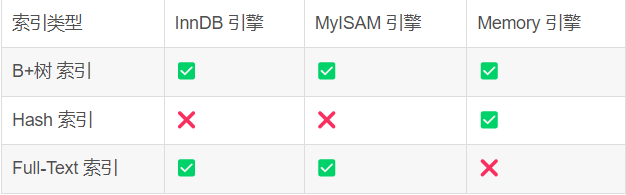
InnoDB is the default storage engine since MySql 5.5, and the B+ tree index is also the most used index type in the MySql storage engine.
When creating a table, the InnoDB storage engine will select different columns as indexes according to different scenarios:
If there is a primary key, the primary key will be used as the index key of the clustered index (primary key index) by default.
If there is no primary key, select the first unique column that does not contain NULL values as the index key of the clustered index.
In the absence of both of the above, InnoDB will automatically generate an implicit auto-increment id column as the index key of the clustered index.
Tips: Other indexes are auxiliary indexes (secondary indexes). The created primary key indexes and secondary indexes use B+ tree indexes by default.
3. Index usage scenarios
The biggest benefit of index is to improve query speed, but index also has disadvantages, for example:
Need to occupy physical space, the larger the amount of data, the more space it takes up.
It takes time to create and maintain indexes, and this time increases as the amount of data increases.
It will reduce the efficiency of adding, deleting, and modifying tables, because every time an index is added, deleted, and modified, the B+ tree needs to be dynamically maintained in order to maintain the order of the index.
When is it appropriate to use indexes?
Fields have uniqueness restrictions, such as a student’s id number.
Fields often used in where query conditions, which can improve the query efficiency of the entire table, if the query condition is not a field, a joint index can be established.
The process is used for the fields of group by and order by, so that there is no need to sort again when querying, because the records in the B+ tree are all sorted after the index is established.
When do you not need to create an index?
For fields that are not used in where group by order by, the value of the index is quick positioning. If the field is not used for positioning, it is usually not necessary to build an index, so the index will take up additional space.
There is a lot of repeated data in the field, and there is no need to create an index. For example: gender field, only men and women, if the records of men and women in the data table are evenly distributed, then no matter which value is searched, half of the data will be obtained. Therefore, there is a query optimization in MySql When a certain value has a high percentage in the data table, the index is generally ignored and a full scan is performed.
There is no need to create indexes when there is too little data in the table.
Frequently updated fields do not need to create indexes. For example, do not create indexes for students’ grades, because the index fields are frequently modified and the order of the B+ tree needs to be maintained. Then the indexes need to be rebuilt frequently. This process will affect the performance of the database.
4. Use of indexes
When creating primary key constraints (primary key), unique constraints (unique), and foreign key constraints (foreign key), indexes for corresponding columns are automatically created.
view index
show index from 表名;
mysql> show index from student;
+———+————+———-+————–+————-+———–+————-+———-+——–+——+————+———+—————+———+————+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+———+————+———-+————–+————-+———–+————-+———-+——–+——+————+———+—————+———+————+
| student | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | | YES | NULL |
+———+————+———-+————–+————-+———–+————-+-
create index
For non-primary keys, non-unique constraints, and non-foreign key fields, secondary indexes can be created.
create index 索引名 on 表名(字段名);
mysql> create index name_index on student(name);
mysql> show index from student;
+———+————+————+————–+————-+———–+————-+———-+——–+——+————+———+—————+———+————+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+———+————+————+————–+————-+———–+————-+———-+——–+——+————+———+—————+———+————+
| student | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | | YES | NULL |
| student | 1 | name_index | 1 | name | A | 0 | NULL | NULL | YES | BTREE | | | YES | NULL |
+———+————+————+————–+————-+———–+————-
Tips: It is best to create an index at the beginning of building a table. If there is a lot of data in a table, creating an index at this time will take up a lot of disk IO and take a long time. During this time, the database cannot be used normally .
delete index
drop index 索引名 on 表名;
mysql> drop index name_index on student;
mysql> show index from student;
+———+————+———-+————–+————-+———–+————-+———-+——–+——+————+———+—————+———+————+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+———+————+———-+————–+————-+———–+————-+———-+——–+——+————+———+—————+———+————+
| student | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | | YES | NULL |
+———+————+———-+————–+————-+———–+————-+-
Tips: If the amount of data is large, deleting the index will also occupy a large amount of disk and cause the database to be unusable.
5. Index data structure
B+ tree vs hash table:
When it comes to data structure, the first thing that comes to mind should be a hash table with a query time complexity of O(1). But the hash table has a fatal flaw that it cannot compare the range of data, but can only query whether it is equal, so first Exclude hash tables.
B+ tree vs binary search tree:
When it comes to the range of query data, the binary tree search tree is definitely a powerful tool. But the original intention of creating an index is to improve query efficiency. If the amount of data is too large, the height of the binary search tree will be very high, so multiple nodes will be generated. Increase the number of database comparisons, resulting in a large amount of disk usage affecting the performance of the database.
B+ tree vs B tree:
Further optimization is needed on the basis of the two-insert search tree. This leads to the B-tree, which is the N-insert search tree. The biggest advantage of the B-tree is that the height of the tree is greatly reduced. Although the number of comparisons has not been reduced, the hard disk I/O The number of times is reduced, and the performance of the database is improved.

Although the B-tree is more suitable for index data structure than the binary insertion search tree, but the B+ tree has made a further improvement on the B-tree and is a data structure tailored for the index.
Features of B+ tree:
1. The B+ tree is an N-ary tree, each node can contain N keys, N keys divide N intervals, and the last key is equivalent to the maximum value.
2. The key of the parent element is repeated in the form of the maximum value in the child element. This ensures that the leaf nodes contain all the keys of the data.
3. The B+ tree will connect the leaf nodes end-to-end in a form similar to a doubly linked list. It is suitable for the common range-based order search in MySQL.

eg: We execute the following query statement:
select * from student where id = 6;
This statement uses the primary key index to query the student whose id is 6. During the query process, the B+ tree will search from top to bottom layer by layer
Compare 6 with the index data (8 16) of the root node, before 8, so according to the search logic of the B+ tree, find the index data (2 5 8) of the second layer.
Compared in the index (2 5 8) of the second layer, 6 is between 5 and 8, so the index data (6 8) of the third layer is found according to the search logic of the B+ tree.
Search in the index data (6 8) of the leaf node, and then we find the row data with the index value 6.
The index and data of the database are stored in the hard disk. We can regard reading a node as an I/O operation of a hard disk. Then the above query process has gone through 3 nodes in total, that is, 3 I/O operations have been performed.
B+ tree storage of tens of millions of data only needs 3-4 layers of height to meet, which means that querying target data from tens of millions of tables requires at most 3-4 disk I/Os, so B+ tree is compared with The biggest advantage of the binary search tree is that the query efficiency is very high, because even in the case of a large amount of data, the disk I/O for querying a data is still maintained at about 3-4 times.
Advantages of B+ tree:
1. As an N-insert search tree, the height is lowered, and the number of I/Os of the hard disk will be reduced during comparison (same as B-tree).
2. B+ tree is more suitable for range query.
3. All queries are finally on the leaf nodes, no matter which element is queried, the number of intermediate comparisons is roughly equal.
4. Since all keys will be reflected in the leaf nodes, non-leaf nodes do not need to store the real records of the table, but only need to store the value of the index column (for example, store an id). In this way, the space occupied by non-leaf nodes is greatly reduced, and further It reduces the IO of the hard disk.

The process of querying data through secondary indexes:
The difference between the primary key index and the B+ tree of the secondary index is as follows:
The actual data is stored in the leaf nodes of the B+ tree indexed by the primary key, and all complete data records are stored in the leaf nodes of the B+ tree indexed by the primary key.
The B+ tree leaf nodes of the secondary index store the primary key value instead of the actual data.
If we use the secondary index query, we will first check the index value of the B+ tree in the secondary index, find the corresponding leaf node, obtain the primary key value, and then query the corresponding leaf node through the B+ tree in the primary key index, and then obtain The entire row of data. This process is called returning to the table, that is, you need to check the B+ tree twice to find the data. But if the queried data can be queried in the B+ tree of the secondary index, then there is no need to query the primary key index. This process of querying results in the B+ tree of the secondary index is called a covering index, that is, you can query the results as long as you query a B+ tree.