
1. What is master-slave synchronization
Master-slave synchronization, also known as master-slave replication, is a high-availability solution provided by MySQL to ensure the consistency of master-slave data. In a production environment, there are many uncontrollable factors, such as the database service being down. In order to ensure high availability of applications, the database must also be highly available. Therefore, in the production environment, the master-standby synchronization will be adopted. In the case of a small application scale, one master and one backup are generally used.
Two benefits of master-slave synchronization
In addition to the above-mentioned database service being down and being able to quickly switch to the standby database to avoid application unavailability, the adoption of master-standby synchronization has the following benefits:
Improve the read concurrency of the database. Most applications have more reads than writes. The master-slave synchronization scheme is adopted. When the scale of use becomes larger and larger, the standby database can be expanded to improve the read capability.
Backup, master and backup synchronization can get a real-time complete backup database.
Quick recovery, when the main database makes an error (such as deleting a table by mistake), quickly restore data through the standby database. For large-scale applications, where the tolerance for data recovery speed is very low, by configuring a standby database that is separated from the data snapshot of the main database by half an hour, when the main database deletes a table by mistake, it can be recovered through the standby database and binlog. Fast recovery, wait up to half an hour.
Three implementation principles of master-slave synchronization
The following figure shows the basic master-standby switchover process

In state 1, the main database is A, and the standby database is B, so the client’s reading and writing are all directly method node A. Since node B is the standby database of node A, standby database B just synchronizes all the updates of A and executes them locally, which can ensure the data consistency between node B and node A.
If a master-standby switchover occurs, it will change from state 1 to state 2, node A becomes the standby database, and node B becomes the master database.
In state 1, although node B is not directly accessed by the client, it is still recommended to set node B (standby database) to read-only (readonly) mode, mainly for the following reasons:
Prevent certain services from accessing the standby database, resulting in misoperation;
Prevent bugs in the switching logic, such as double writing during the switching process, resulting in inconsistency between the master and backup;
You can use the readonly state to judge the role of the node;
Note: readonly is invalid for super administrators, and the thread used for synchronous updates has super permissions, so it is possible to modify the standby database.
Next, let’s look at the flow chart from node A to node B:

In fact, a long connection is maintained between the standby database B and the main database A, and there is a thread (dump_thread) in the main database A, which is dedicated to the long connection between the service and the standby database B. The complete process of log synchronization is as follows:
1. Use the change master command on the standby database B to set the relevant information of the main database A and where to start requesting the binlog;
2. Execute the start slave command on the standby database B, and the standby database will start two threads, namely io_thread and sql_thread, among which io_thread is responsible for communicating with the main database;
3. After the main database A verifies the information, it reads the binlog locally according to the location transferred from the backup database B and passes it to B;
4. After the standby database gets the binlog, it writes it to a local file, which is called a relay log;
5. sql_thread reads the transfer log, parses out the command and executes it;
4. Three formats of binlog
The format of binlog actually consists of two formats, one is statement and the other is row. There is also a mixed format, which is actually a mixture of the first two.
In order to explain the difference between several log formats, we create a table and write some data.
mysql> create table t(
id int(11) not null,
a int(11) default null,
t_modified timestamp not null default current_timestamp,
primary key (id),
key a(a),
key t_modified (t_modified)
)ENGINE=InnoDB;
insert into t values(1,1,’2018-11-13′)
insert into t values(2,2,’2018-11-12′)
insert into t values(3,3,’2018-11-11′)
insert into t values(4,4,’2018-11-10′)
insert into t values(5,5,’2018-11-09′)
Then, we execute the delete statement on this table:
Note that the following statement contains comments. If you use the MySQL client to do this experiment, remember to add the -c parameter, otherwise the client will automatically remove the comments.
mysql>delete from t /*comment*/ where a>=4 and t_modified <=’2018-11-10′ limit 1;
We can use the following command to view the contents of the binlog:
mysql> show binlog events in ‘master.000001’
It can be seen that when binlog_format=statement, the original sql is recorded in the binlog:

Now, let’s look at the output in Figure 3.
You can ignore the first line SET @@SESSION.GTID_NEXT=’ANONYMOUS’ first, and we will mention it later in the article when introducing the master-standby switchover;
The second line is a BEGIN, which corresponds to the commit in the fourth line, indicating that there is a transaction in the middle;
The third line is the statement that is actually executed. It can be seen that there is a “use ‘test'” command before the actually executed delete command. This command is not executed by us actively, but is added by MySQL itself according to the database where the current table to be operated is located. This can ensure that when the log is transferred to the standby database for execution, no matter which library the current worker thread is in, it can be correctly updated to the table t of the test library.
The delete statement after the use ‘test’ command is the original text of the SQL we entered. It can be seen that the binlog “faithfully” records the SQL commands, and even records the comments.
The last line is a COMMIT. You can see that it says xid=61.
To illustrate the difference between statement and row formats, let’s take a look at the execution effect diagram of this delete command:

It can be seen that running this delete command produces a warning, because the current binlog is set in the statement format, and there is a limit in the statement, so this command may be unsafe.
Why do you say that? This is because delete with limit may cause inconsistency between the primary and backup data. Like the example above:
If the delete statement uses index a, then the first row satisfying the condition will be found according to index a, that is to say, the row a=4 is deleted;
But if the index t_modified is used, then the row t_modified=’2018-11-09′, which is a=5, is deleted.
In the statement format, the original text of the statement is recorded in the binlog, so there may be such a situation: when the main database executes this SQL statement, the index a is used; while the standby database executes this SQL statement Sometimes, the index t_modified is used. Therefore, MySQL considers it risky to write like this.
So, if I change the binlog format to binlog_format=’row’, will there be no such problem? Let’s take a look at the contents of binog at this time.

It can be seen that compared with the binlog in the statement format, the BEGIN and COMMIT before and after are the same. However, the original text of the SQL statement is missing in the binlog in row format, but replaced by two events: Table_map and Delete_rows.
Table_map event, used to indicate that the table to be operated next is the table t of the test library;
Delete_rows event, used to define the behavior of deletion.
In fact, we cannot see the detailed information through Figure 5, and we need to use the mysqlbinlog tool to parse and view the contents of the binlog with the following command. Because the information in Figure 5 shows that the binlog of this transaction starts from the position 8900, so you can use the start-position parameter to specify that the log at this position should be parsed.
mysqlbinlog -vv data/master.000001 –start-position=8900;
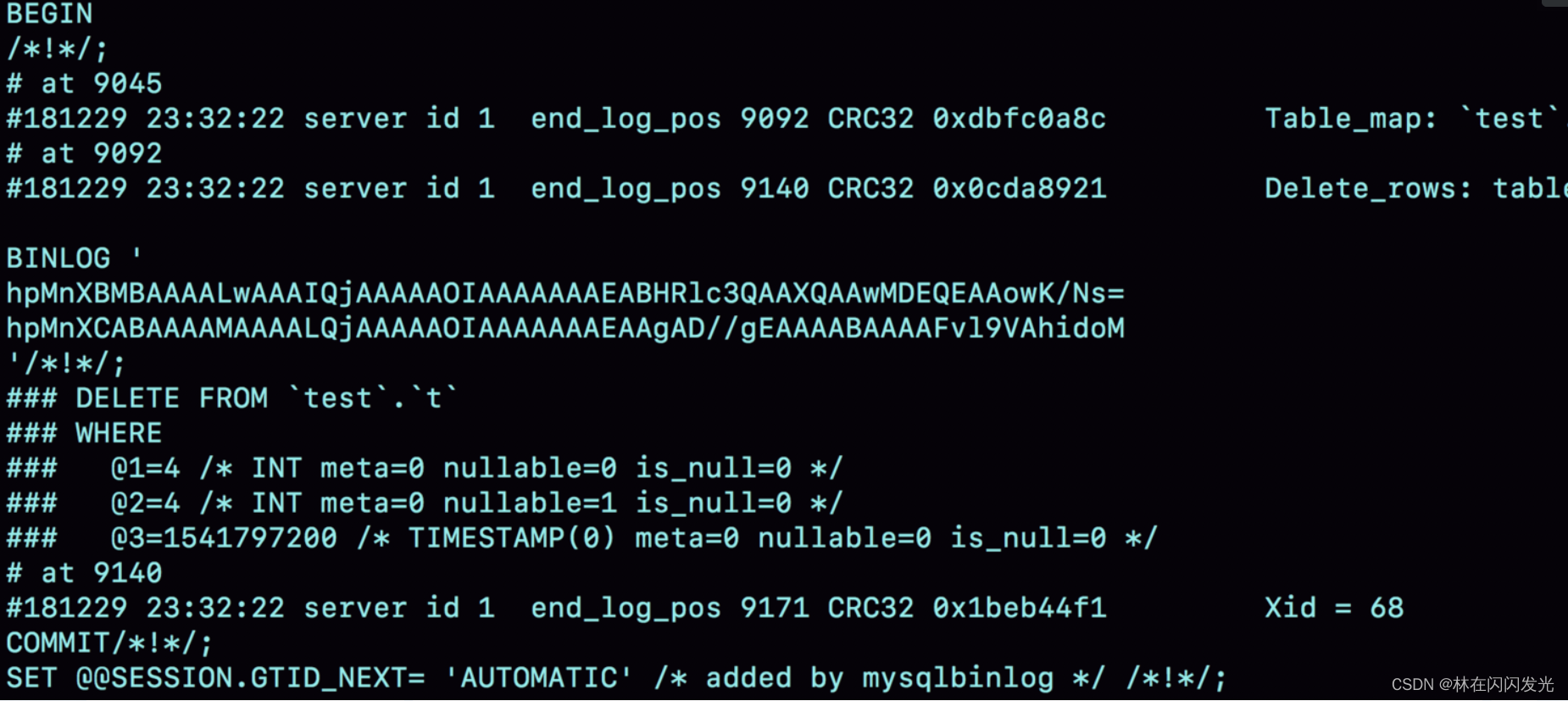
From this figure, we can see the following information:
1. server id 1, indicating that the transaction is executed on the library with server_id=1.
2. Each event has a CRC32 value, because I set the parameter binlog_checksum to CRC32.
3. The Table_map event is the same as seen in Figure 5, showing the table to be opened next, mapped to the number 226. Now our SQL statement only operates one table, what if we want to operate multiple tables? Each table has a corresponding Table_map event, which will be mapped to a separate number, which is used to distinguish operations on different tables.
We use the -vv parameter in the mysqlbinlog command to parse out the content, so you can see the values of each field from the results (for example, @1=4, @2=4 these values).
4. The default configuration of binlog_row_image is FULL, so Delete_event contains the values of all fields of the deleted row. If binlog_row_image is set to MINIMAL, only the necessary information will be recorded. In this example, only the information of id=4 will be recorded.
5. The last Xid event is used to indicate that the transaction has been submitted correctly.
You can see that when the binlog_format uses the row format, the primary key id of the actually deleted row is recorded in the binlog, so that when the binlog is transferred to the standby database, the row with id=4 will definitely be deleted, and there will be no primary and standby deletions. The problem of different lines.
5. Why is there a binlog in mixd format?
From the above description, we can clearly see the advantages and disadvantages of the statement and row formats:
statement: The format saves space and only needs to record sql statements. However, there may be inconsistencies between the master and backup;
row: There will be no inconsistency between the master and slave. But the format is very space consuming and needs to record all modified lines.
The mixed format means that MySQL will judge whether this SQL statement may cause an inconsistency between the master and the backup. If possible, use the row format, otherwise use the statement format.
Therefore, for online scenes, it is definitely unreasonable to set it to the statement format, at least it must be set to the mixed format.
In fact, more and more row formats are used now, and one of the benefits is to restore data:
When the delete statement is executed, it is found that it has been deleted by mistake, and the information in the binlog can be directly converted into an insert statement for insertion.
After executing the insert statement, it is found that the error has been inserted, and the information in the binlog can be directly converted into a delete statement and inserted
If the update statement is executed, the binlog will record the information before and after the modification, so as to recover
Six common two main and standby switching processes
M-S structure
M-S structure, two nodes, one as the main library and one as the standby library, the two nodes are not allowed to exchange roles.
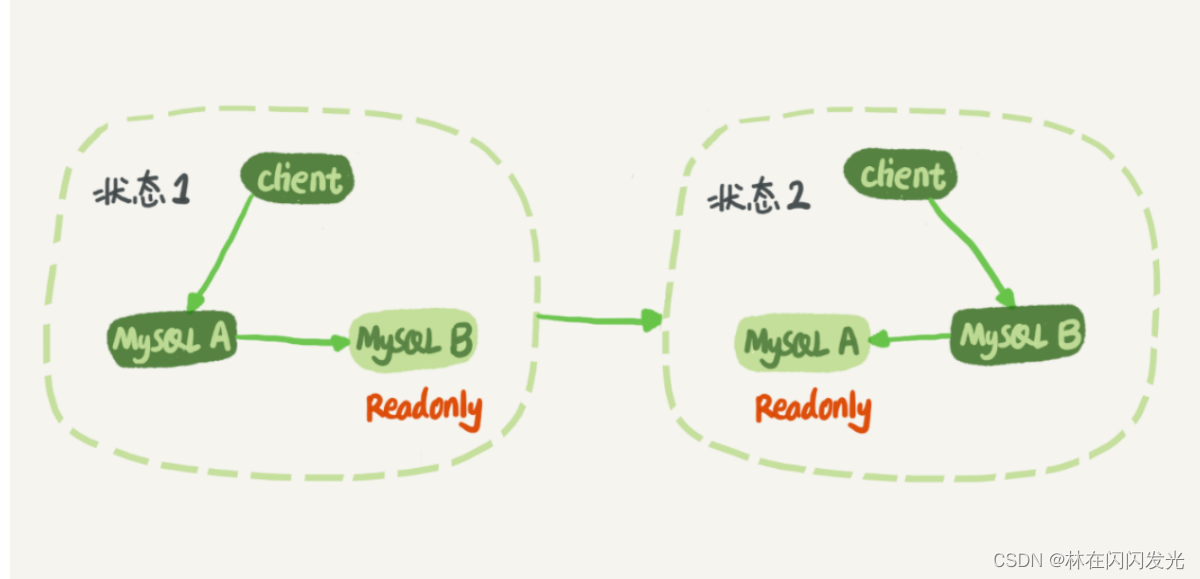
In state 1, the client directly accesses node A for both reading and writing, and node B is the standby database of A, but only synchronizes the updates of A and executes them locally. This keeps the data of nodes B and A the same.
When switching is required, switch to state 2. At this time, the client reads and writes and accesses node B, and node A is the standby database of B.
double M structure
Double M structure, two nodes, one as the main database, one as the standby database, allowing the two nodes to exchange roles.
There is always a master-backup relationship between nodes A and B. In this way, there is no need to modify the master-standby relationship during the switchover.
Cyclic replication problem of double M structure
In actual production and use, the double M structure is used in most cases. However, there is still a problem to be solved in the double M structure.
When the business logic is updated on node A, binlog will be generated and synchronized to node B. After the synchronization of node B is completed, a binlog will also be generated. (log_slave_updates is set to on, indicating that the standby database will also generate binlog).
When node A is also the standby database of node B, the binlog of node B will also be sent to node A, resulting in cyclic replication.
Solution:
Set the server-id of the node, which must be different, otherwise it is not allowed to set the active and standby structure
When the standby database replays the binlog after receiving it, it will record the same server-id as the original record, that is, whoever generated it belongs to him.
When each node receives the binlog, it will judge the server-id, and discard it if it is its own.
Process after resolution:
When the business logic is updated on node A, a binlog with node A’s server-id will be generated.
Node B receives the binlog sent by node A, and after execution is complete, it will generate a binlog with node A’s server-id.
After node A receives the binlog, it finds that it belongs to itself, so it discards it. The infinite loop is broken here.