
1. From the perspective of whether the model is overfitting or underfitting
Most attention modules are parameterized, and adding attention modules will increase the complexity of the model.
If the model is underfitting before attention is added, adding parameters is beneficial to model learning and performance will improve.
If the model is overfitting before attention is added, increasing the parameters may exacerbate the overfitting problem, and the performance may remain unchanged or decline.
Knowing that the big brother pprp did an experiment to verify the above conjecture, he used 10% of the data in the cifar10 data set for verification, and chose wideresnet for the model. The model can flexibly adjust the capacity of the model by adjusting the width of the model.
Specifically, the model capacity is getting higher and higher from top to bottom. The figure below shows the convergence results of each model on the training set and validation set.
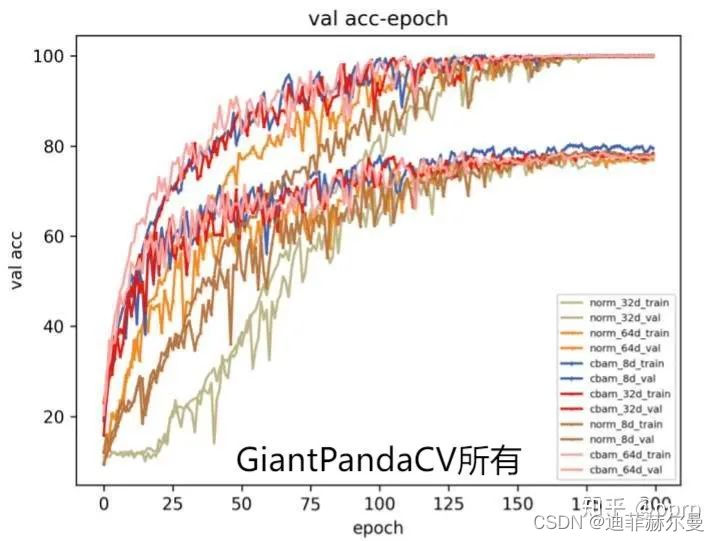
Several phenomena can be found:
As the width increases, the phenomenon of model overfitting will increase, specifically, the accuracy of the validation set will become lower.
Comparing cbam with norm, it can be found that using cbam on the basis of 8d (may still be underfitting) can achieve the highest result of the verification set, and the accuracy rate is almost the same after using cbam on the basis of 64d (possibly overfitting). .
Another interesting phenomenon is that in terms of convergence speed, it generally conforms to the trend that the wider the model, the faster the convergence speed (consistent with our known conclusion, the wider model loss landscape is smoother and easier to converge)
“The above is the first angle, the other angle may not be so accurate, just provide an intuition”
2. From the perspective of model experience field
On this point, my opinion is a bit different from that of Zhihu boss pprp. I will put his opinion first.
We know that CNN is a highly localized model, usually using 3×3 convolution to scan the entire picture, and extract information layer by layer. The receptive field superposition is also constructed by multi-layer superposition. For example, the theoretical receptive field of two 3×3 convolutions is 5×5, but the actual receptive field is not that large.
What are the functions of various attention modules? They can make up for the problem of too strong locality and insufficient globality of cnn, so as to obtain global context information. Why is context information important? You can see a picture from CoConv.

Simply looking at picture a may not know what the object is at all, but when there is picture b, after knowing that this is a kitchen, you can recognize that the object is a kitchen glove. Therefore, the attention module has the ability to make the model look wider. The recent emergence of vision transformers is also related to attention. For example, the Non Local Block module is very similar to the self-attention in ViT. The poor performance of the vision transformer on small data sets can also be explained from this perspective, because it is too focused on globality (and the number of parameters is relatively large), it is very easy to overfit, and its ability to memorize data sets is also very strong, so only Large-scale data set pre-training can achieve better results. (Thanks to Teacher Li Mu for the series of videos!) Going back to this question, the influence of the attention module on the receptive field, intuitively speaking, will increase the size of the receptive field of the model. In theory, the best situation should be that the actual receptive field of the model (not the theoretical receptive field) matches the size of the target.
If the receptive field of the model is sufficient to fit the target in the data set before adding the attention module, then adding the attention module is a bit superfluous. However, since the actual receptive field will change, it may be possible to adjust the actual receptive field to be close to the target size even if the attention module is added, so that the model may maintain the same performance.
If the receptive field of the model is insufficient before adding the attention module, and even the theoretical receptive field cannot reach the size of the target (actual receptive field size < theoretical receptive field size), then adding the attention module at this time can play a very important role. Good effect, performance may be improved to a certain extent.
From this point of view, the subject only used two convolutional layers, and then started to use the CBAM module, which is likely to be due to insufficient receptive fields. But why the performance will drop? There may be other factors. You can consider building a similar baseline, such as ResNet20 with residuals, or a smaller network, and then add an attention module on top of it. The above conclusions are not rigorous, comments and discussions are welcome.
The following is my personal opinion, not rigorous ?, please treat it rationally
I think the principle of the attention mechanism is to make reasonable use of limited visual information processing resources. It must be necessary to select a specific part of the visual area and then focus on it. In this case, the model will only focus on him. The part that is considered important, thus ignoring other parts of the information. (In other words, the attention is too “strong”)
Because I found in the experiment that the attention mechanism almost always brings about an increase in precision and a decrease in recall rate. I think this phenomenon can explain my thoughts to a certain extent.
Of course, this is the result of my personal speculation. It has not been confirmed. Please treat it rationally. If you have other ideas, you are welcome to discuss them in the comment area.
After reading this article, everyone should have a certain understanding of these questions, and I will briefly answer them below.
Where is the best place to add the attention module?
I don’t think it’s good to say where to add. I still need to experiment more. I will update some attention addition configuration files in my Github. You can refer to it. Maybe which addition will increase in your data set. ordered
Can multiple of the same or different attention modules be added?
Yes, several complementary attention modules will bring better results, and different amounts of the same attention will have different effects
Which attention module should I use for my dataset?
Experiment to find out the truth
Can weights still be used after adding the attention module?
can! YOLOv5 will automatically match some of the available ones, don’t worry about how to change them, just write the weight path, it’s better to use it than not
How to set the parameters of individual attention modules?
I’m not too sure about this, let’s experiment more.