
1. Redis implements distributed Session management
1 Management Mechanism
The session management of redis is to use the session management solution provided by spring to transfer an application session to Redis for storage, and all session requests in the entire application will go to redis to obtain the corresponding session data.
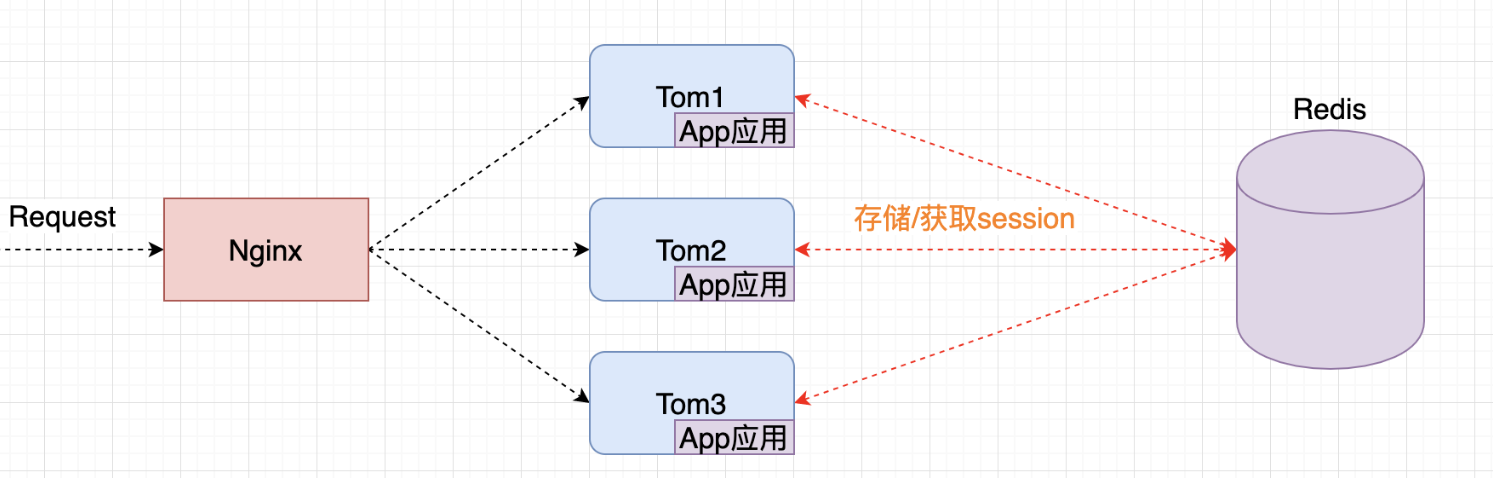
2 Develop Session Management
1. Introduce dependencies
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
</dependency>
2. Develop Session management configuration class
@Configuration
@EnableRedisHttpSession
public class RedisSessionManager {
}
3. Just pack and test
2. Cache penetration and avalanche
cache penetration
concept
By default, when a user requests data, they will first look it up in the cache (Redis). If the cache is not hit, all of them will be transferred to the database, which will cause great pressure on the database and may cause the database to crash. Some people in network security also maliciously use this method to attack, which is called flood attack.
The user wants to query a piece of data, but finds that the redis memory database does not exist, that is, the cache is not hit, so he queries the database of the persistence layer, and finds that there is no data, so this query fails. When there are many users, the cache does not hit (second kill), so they all request the persistence layer database. This will put a lot of pressure on the persistence layer database, which is equivalent to cache penetration
solution
bloom filter
All possible query parameters are stored in the form of Hash to quickly determine whether the value exists. At the control layer, interception and verification are performed first. If the verification fails, it will be returned directly, reducing the pressure on the storage system.
Cache empty objects
If a request is not found in the cache or the database, an empty object will be used in the cache to process subsequent requests.
This has a drawback: storing empty objects also requires space, a large number of empty objects will consume a certain amount of space, and the storage efficiency is not high. The way to solve this defect is to set a shorter expiration time
Even if the expiration time is set for the null value, there will still be inconsistencies between the data in the cache layer and the storage layer for a period of time, which will affect the business that needs to maintain consistency.
Cache breakdown (too large, cache expired)
concept
Compared with cache penetration, cache penetration is more purposeful. For an existing key, when the cache expires, there are a large number of requests at the same time. These requests will penetrate to the DB, resulting in a large amount of instantaneous DB requests and sudden pressure. increase. This means that the cache is broken down, but the cache for one of the keys is not available, causing the breakdown, but other keys can still use the cached response.
For example, on the hot search rankings, if a hot news is accessed in large numbers at the same time, it may cause a cache breakdown.
solution
Set hotspot data to never expire
In this way, there will be no hot data expiration, but when the Redis memory space is full, some data will be cleaned up, and this solution will take up space. Once the hot data increases, it will take up part of the space.
Add mutex (distributed lock)
Before accessing the key, use SETNX (set if not exists) to set another short-term key to lock the access of the current key, and delete the short-term key after the access is over. It is guaranteed that only one thread accesses at a time. In this way, the requirements for locks are very high.
cache avalanche
concept
A large number of keys are set with the same expiration time, causing all caches to fail at the same time, resulting in a large amount of instantaneous DB requests, a sudden increase in pressure, and an avalanche.
Cache avalanche means that a large amount of data in the cache reaches the expiration time, and the query data volume is huge, causing excessive pressure on the database or even downtime. Different from the cache breakdown, the cache breakdown refers to concurrently querying the same piece of data, and the cache avalanche means that different data have expired, and many data cannot be found, so the database is checked.
solution
redis high availability
The meaning of this idea is that since redis may hang up, I will add a few more redis, so that after one hangs up, the others can continue to work. In fact, it is the cluster built
current limit downgrade
The idea of this solution is to control the number of threads that read the database and write the cache by adding locks or queues after the cache expires. For example, only one thread is allowed to query data and write cache for a certain key, while other threads wait.
data preheating
The meaning of data heating is that before the official deployment, I first access the possible data first, so that some data that may be accessed in large quantities will be loaded into the cache. Manually trigger the loading of different keys in the cache before large concurrent accesses are about to occur, and set different expiration times to make the cache failure time as uniform as possible.