AI operation refers to the neural network algorithm represented by “deep learning”, which requires the system to be able to efficiently process a large number of unstructured data (text, video, image, voice, etc.). The hardware is required to have efficient linear algebra operation capability, and the calculation task has the following characteristics: simple unit calculation task, low logic control difficulty, but large parallel calculation amount and many parameters. There is a high demand for multi-core parallel computing, on-chip storage, bandwidth, and low latency memory access for chips.
The richness of AI application scenarios has brought many fragmentation requirements, and processors adapted to various functions based on this have been constantly derived.
The increasing volume of AI and the strengths of “X” PU
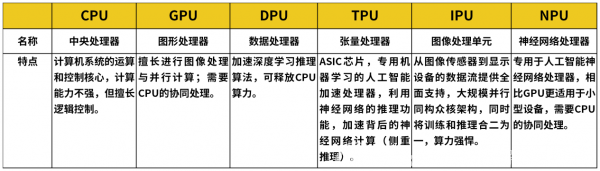
CPU
The CPU, also known as the Central Processing Unit, is the computing and control core of a computer system. It is mainly responsible for multitask management and scheduling, and has strong universality. It is the core leadership component of a computer, similar to the human brain. However, its computing power is not strong and it is better at logical control.
It is precisely because the parallel computing power of the CPU is not very strong that few people prioritize directly training models on the CPU. However, chip giant Intel has chosen this path.
Like Intel? Zhiqiang? The scalable processor, which is an AI build-in CPU, has greatly improved its support for model training. Last year, a paper published by researchers from institutions such as Rice University, Ant Group, and Intel showed that AI software running on consumer grade CPUs has a training speed of 15 times that of GPUs for deep neural networks. Additionally, compared to graphics memory CPUs, the memory is more scalable, and many recommended algorithms, sorting models Applications such as image/image recognition are already using CPUs as basic computing devices on a large scale.
Compared to expensive GPUs, CPUs are actually a cost-effective training hardware and are also very suitable for deep learning models for customers in industries such as manufacturing, image processing, and analysis that require high accuracy of results while also considering cost considerations.
GPU
GPU, also known as Graphics Processing Unit, uses a large number of computing units and ultra long pipelines, excels in image processing and parallel computing.
For complex single computing tasks, the CPU has higher execution efficiency and stronger universality; For the simple calculation of matrix based multi pixel points in graphics and images, it is more suitable to use GPU for processing, which is also known as the “crowd tactics”. In the field of AI, deep learning for image recognition, machine learning for decision-making and reasoning, and supercomputing all require large-scale parallel computing, making GPU architecture more suitable.
The increasing volume of AI and the strengths of “X” PU
Computing grid for multi-core CPUs and GPUs (green squares in the figure represent computing units)
There is another significant difference between CPU and GPU: the CPU can act independently to handle complex logical operations and different data types, but when it is necessary to handle a large amount of uniformly typed data, GPU can be called for parallel computing. But the GPU cannot work alone and must be controlled and called by the CPU to function.
In the AI computing field, NVIDIA’s GPUs account for almost the vast majority of the market, but in recent years, many domestic enterprises have also entered high-end GPUs. For example, Muxi’s first heterogeneous GPU product using 7nm technology has been taped, and Biren recently released the BR100 with a single chip peak computing power reaching the PFLOPS level. Companies such as Suiyuan Technology, Black Sesame, and Horizon are also making efforts towards high-end GPUs.
DPU
DPU, also known as Data Processing Unit, is used to optimize convolutional neural networks and is widely used to accelerate deep learning inference algorithms.
When the CPU computing power is released and encounters a bottleneck, the DPU can unload the CPU’s basic layer applications (such as network protocol processing, encryption and decryption, data compression, etc.), thereby releasing the CPU’s inefficient application end computing power and concentrating it on the upper layer applications. Unlike GPU, DPU is mainly used for data analysis and processing to improve the efficiency of data transmission, while GPU focuses on accelerating data computation. Therefore, DPU is expected to become a key chip for unleashing CPU computing power, and form complementary advantages with CPU and GPU to improve the computing power ceiling.
The DPU also has a high-performance network interface that can parse, process data at line speed or the available speed in the network, and efficiently transfer data to the GPU and CPU.
After acquiring Mellanox, NVIDIA launched its BlueField DPU series with its existing ConnectX series high-speed network card technology, becoming a benchmark in the DPU track. NVIDIA CEO Huang Renxun has also stated: “DPU will become one of the three pillars of future computing, and the standard configuration of future data centers will be ‘CPU+DPU+GPU’. The CPU is used for general-purpose computing, GPU is used for accelerated computing, and DPU is used for data processing
The current DPU market has become a battleground for various giants and startups. In addition to companies such as Nvidia starting to layout the DPU industry, major cloud service providers such as Alibaba and Huawei are gradually entering the DPU industry. Other companies include Xinqiyuan, Dayu Zhixin, Xingyun Zhilian, Zhongke Yushu, Yunbao Intelligent, and others.
TPU
TPU: Tensor Processing Unit is an ASIC chip developed by Google specifically to accelerate the computing power of deep neural networks, a specialized artificial intelligence acceleration processor for machine learning.
AI systems typically involve training and inference processes. Simply put, the training process refers to the process of learning from existing data and acquiring certain abilities; The reasoning process refers to using these abilities to complete specific tasks (such as classification, recognition, etc.) on new data; Reasoning is the process of putting the results of deep learning training into use.
There is an old saying: the efficiency of a universal tool is never comparable to that of a specialized tool. Compared to the CPU and GPU of the same period, TPU can provide a performance improvement of 15-30 times and an efficiency improvement of 30-80 times (performance/watt). In addition, using GDDR5 memory commonly used by GPUs in TPUs can increase the performance TPOS index by another three times, and increase the energy efficiency ratio index TOPS/Watt to 70 times that of GPUs and 200 times that of CPUs.
When the news of TPU was just released in 2016, Norman Joupi, a senior hardware engineer at Google, specifically mentioned in the Google Research blog that TPU only took 22 days from testing to mass production, and its performance pushed artificial intelligence technology forward for almost 7 years, equivalent to the time of the third generation of Moore’s Law.
IPU
IPU: Intelligent Processing Unit that provides comprehensive support for data flow from image sensors to display devices, connecting to related devices such as cameras, monitors, graphics accelerators, television encoders, and decoders. Related image processing and operations include sensor image signal processing, display processing, image conversion, as well as synchronization and control functions. It adopts a large-scale parallel isomorphic crowdsource architecture, which combines training and reasoning, providing a new technical architecture for AI computing and the ability to handle both tasks.
IPU is a concept first proposed by Graphcore, a British AI chip startup. Graphcore’s first generation IPU is now used in Microsoft Azure cloud and Dell-EMC servers, bringing a leap in performance improvement to AI algorithms and broader innovation space and opportunities for developers.
At present, IPU is becoming the third largest deployment platform after GPU and Google TPU. IPU based applications have covered various application scenarios of machine learning, including natural language processing, image/video processing, timing analysis, recommendation/ranking and probability model.
In 2021, Intel launched IPU technology and recently collaborated with Google to design a new custom infrastructure processing unit (IPU) chip E2000, codenamed “Mount Evans”, to reduce the main CPU load in data centers and handle data intensive cloud workloads more effectively and securely.
NPU
The manufacturing costs of CPUs and GPUs are relatively high, and the power consumption is also relatively high. In addition, the amount of data that needs to be calculated in AI scenarios is increasing day by day. Therefore, an efficient intelligent processor for deep learning of neural networks, namely NPU, has emerged.
NPU, also known as Neural Network Processing Unit, uses circuits to simulate human neuronal and synaptic structures. Used to accelerate the operation of neural networks and solve the problem of low efficiency of traditional chips in neural network operations, particularly adept at processing massive multimedia data such as videos and images.
Compared to the thousands of instructions required for CPU and GPU processors to run, NPUs can complete with just one or a few instructions, and their performance can reach 118 times that of GPUs under the same power consumption. Therefore, they have significant advantages in deep learning processing efficiency. At present, NPUs are mostly applied to AI reasoning calculation on the end side, and are also widely used in video codec operation, natural language processing, and data analysis on the cloud side. Some NPUs can also be used for AI training.
For example, in the SoC of mobile phones, the CPU is responsible for computing and overall coordination, while the GPU is responsible for the image related part and the NPU is responsible for the AI related part. The workflow is that any work must first pass through the CPU, and the CPU then determines who to assign based on the nature of this piece of work. If it is a graphical calculation, it will be assigned to the GPU, and if it is an AI calculation requirement, it will be assigned to the NPU.
Specific applications of NPU include: attendance machine based on face recognition, palmprint recognition based on DHN (deep hash network), automatic garbage classification based on image classification, autonomous vehicle, automatic focus camera, monitoring system, etc.
In 2014, the Chen Tianshi scientific research team of the Chinese Academy of Sciences published a series of DianNano papers, which immediately swept the architecture industry and opened the way for the design of specialized artificial intelligence chips. Later, Cambrian Technology under the Chinese Academy of Sciences launched its first generation NPU, Cambrian 1A, which was used in the Huawei Qilin 970 chip. Huawei also launched its self-developed NPU based on the DaVince architecture, while Alibaba launched an NPU with a “light” architecture.
With the changes in chip construction methods, a large number of heterogeneous processor solutions have also been derived, with each chip making different choices regarding processor performance, optimization goals, required data throughput, and data flow. Among these major categories of processor chips, IPU and DPU are leading the way in terms of development speed. With the 5G edge cloud, automatic driving, vehicle road collaboration, financial computing, etc. bringing more and more data, the market value of various “X” PUs is rising.https://www.stoneitech.com/