
Perhaps the last decade’s breakthrough in computer vision and machine learning was the invention of GANs (generative adversarial networks) — an approach that introduced the possibility of going beyond what was already in the data, a stepping stone to a whole new field now called Model generatively. However, after a booming phase, GANs start to face a plateau, where most methods struggle to solve some of the bottlenecks faced by adversarial methods. This is not a problem of a single method, but of the adversarial nature of the problem itself. Some of the main bottlenecks of GANs are:
Image generation lacks variety
mode crash
Multimodal Distribution Problem Learning
training time is too long
Not easy to train due to the adversarial nature of the problem formulation
There is another family of likelihood-based methods (e.g. Markov random fields) which have been around for quite some time but failed to gain significant impact due to the complexity of implementation and formulation for each problem . One such approach is the “diffusion model” – an approach that draws inspiration from the physical process of gas diffusion and attempts to model the same phenomenon across multiple scientific fields. However, in the field of image generation, their applications have recently become more apparent. Mainly because we now have more computing power to test complex algorithms that were not possible in the past.
A standard diffusion model has two main process domains: forward diffusion and backward diffusion. During the forward diffusion stage, the image is polluted with gradually introduced noise until the image becomes completely random noise. In the reverse process, data is recovered from Gaussian noise by progressively removing prediction noise at each time step using a series of Markov chains.

Diffusion models have recently shown remarkable performance in image generation tasks and have replaced the performance of GANs in tasks such as image synthesis. These models were also able to produce more diverse images and were shown to be immune to mode collapse. This is due to the ability of diffusion models to preserve the semantic structure of data. However, these models are computationally demanding and require very large amounts of memory for training, making it impossible for most researchers to even attempt this approach. This is because all Markov states need to be predicted in memory at all times, which means multiple instances of large deep networks are always in memory. Furthermore, the training time of these methods also becomes too high (e.g., days to months), as these models tend to get bogged down in the fine-grained, imperceptible complexity in the image data. It is important to note, however, that this fine-grained image generation is also one of the main strengths of diffusion models, so using them is a contradiction.
Another very well-known family of methods from the NLP field are transformers. They have been very successful in language modeling and building conversational AI tools. In vision applications, transformers exhibit the advantages of generalization and adaptation, making them suitable for general learning. They capture semantic structure in text and even images better than other techniques. However, transformers are data-intensive compared to other methods, and face a performance-wise platform in many vision domains.
latent diffusion model
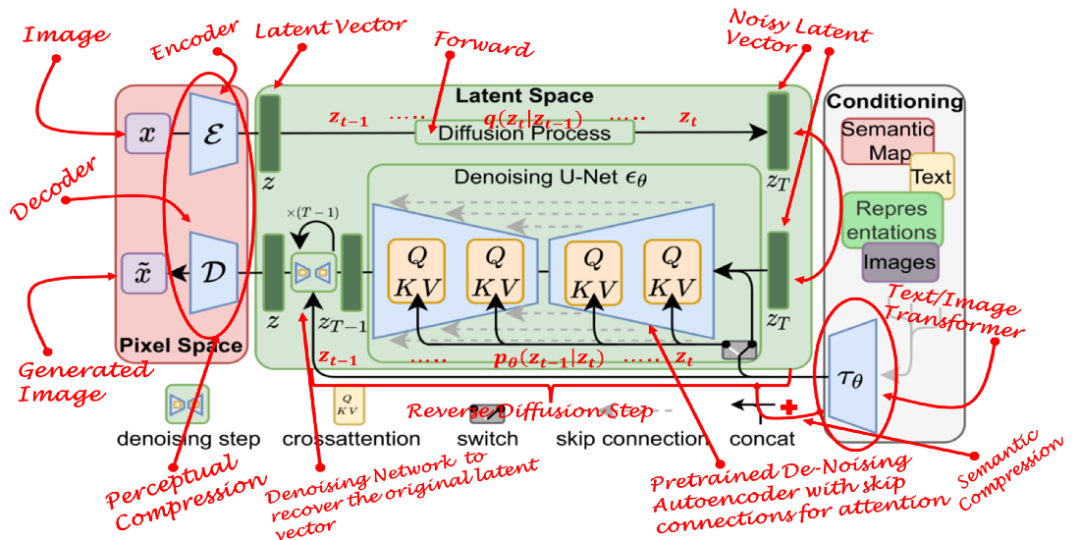
A recently proposed approach leverages the perceptual power of GANs, the detail-preserving power of diffusion models, and the semantic power of transformers, merging the three together. The technique is called the “latent diffusion model” (LDM) by the authors. LDMs have proven themselves to be more robust and efficient than all the aforementioned models. Compared to other methods, they not only save memory, but also produce diverse, highly detailed images that preserve the semantic structure of the data. In short, LDM is the application of a diffusion process in latent space instead of pixel space, while incorporating semantic feedback from the transformer.
Any generative learning method has two main stages: perceptual compression and semantic compression.
compressed sensing
In the perceptually compressed learning stage, learning methods must encapsulate data into abstract representations by removing high-frequency details. This step is necessary to build an invariant and robust representation of the environment. GANs are good at providing this perceptual compression. They do this by projecting high-dimensional redundant data from pixel space into a hyperspace called latent space. A latent vector in latent space is a compressed form of the original pixel image, which can effectively replace the original image.
More specifically, autoencoder (AE) structures are structures that capture perceptual compression. The encoder in AE projects high-dimensional data to the latent space, and the decoder recovers the image from the latent space.
semantic compression
In the second stage of learning, image generation methods must be able to capture the semantic structure present in the data. This conceptual and semantic structure preserves the context and interrelationships of various objects in an image. Transformers are good at capturing semantic structure in text and images. The combination of the generalization ability of transformers and the detail-preserving ability of diffusion models offers the best of both worlds and provides an ability to generate fine-grained highly detailed images while preserving the semantic structure in the images.
Perceptual loss
Autoencoders in LDM capture the perceptual structure of data by projecting it into a latent space. The authors train this autoencoder using a special loss function called “perceptual loss”. This loss function ensures that the reconstruction is confined within the image manifold and reduces blurring that can occur when using pixel-space losses such as L1/L2 losses.
Diffusion loss
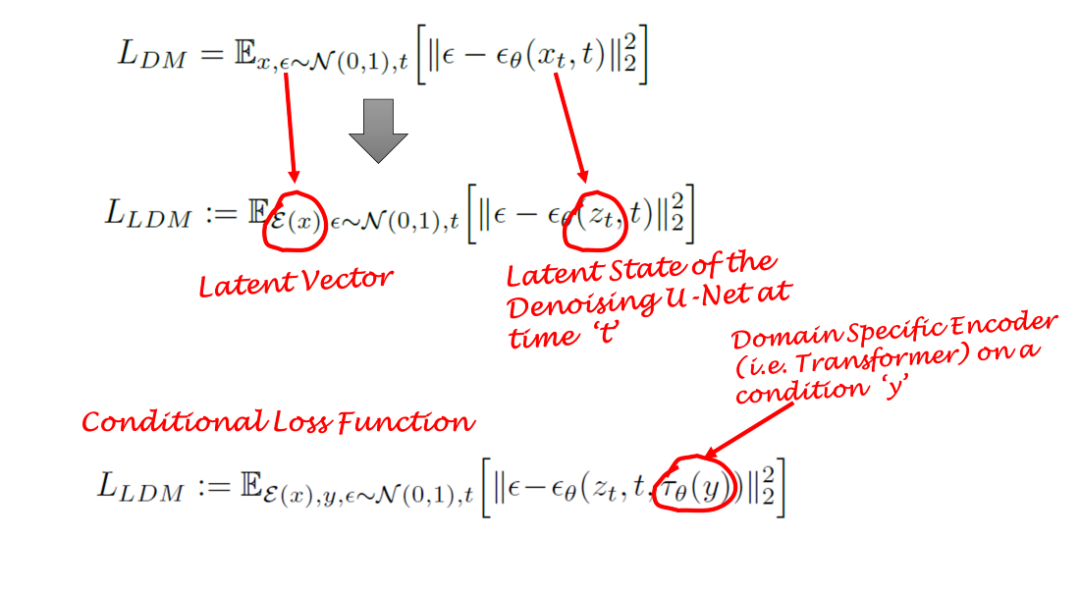
Diffusion models learn data distributions by progressively removing noise from normally distributed variables. In other words, DMs employ reverse Markov chains of length T. This also means that DMs can be modeled as a sequence of T denoising autoencoders with time steps T = 1,…,T. This is represented by εθ in the following formula. Note that the loss function relies on latent vectors rather than pixel space.
conditional diffusion
The diffusion model is a conditional model that relies on priors. In image generation tasks, priors are usually text, images, or semantic maps. To obtain a latent representation for this situation, a transformer (e.g. CLIP) is used, which embeds text/images into a latent vector `τ`. Therefore, the final loss function depends not only on the original image latent space, but also on the conditional latent embedding.
attention mechanism
The backbone of LDM is the U-Net autoencoder with sparse connections providing a cross-attention mechanism [6]. The Transformer network encodes conditional text/images into latent embeddings, which are then mapped to intermediate layers of U-Net via cross-attention layers. This cross-attention layer implements attention(Q,K,V) = softmax(QKT/✔)V, while Q, K and V are learnable projection matrices.
text-to-image synthesis
We use the latest official implementation of LDM v4 in python to generate images. In text-to-image synthesis, LDM uses the pre-trained CLIP model [7], which provides generic transformer-based embeddings for multiple modalities such as text and images. The output of the transformer model is then fed into LDM’s python API `diffusers`. There are some parameters that can also be adjusted (e.g. no. Diffusion step, seed, image size, etc.). Diffusion loss

image-to-image synthesis
The same setup works for image-to-image synthesis, however, requires input sample images as reference images. The resulting images are semantically and visually similar to the reference image. This process is conceptually similar to style-based GAN models, however, it does a better job of preserving the semantic structure of images.

in conclusion
We have introduced a recent development in the field of image generation called latent diffusion models. LDM is robust in generating high-resolution images of different backgrounds with fine details, while also preserving the semantic structure of the images. Therefore, LDM is an advancement in image generation and in particular deep learning. If you’re still wondering about “stable diffusion models”, this is just a rebranding of LDM applied to high-resolution images, while using CLIP as a text encoder.