
I confess that I cried in my compiler class in college, and then chose to become a machine learning engineer, thinking I would never have to worry about compilers again.
However, as I learned more about how the ML model was put into production, questions about the compiler kept popping up. In many cases, especially with edge equipment run ML model, model of success still depends on the hardware to run it (https://hardwarelottery.github.io/). Therefore, it is important to understand the compilation and optimization of the model, as well as how the model runs on different hardware accelerators.
Ideally, we wouldn’t need to pay special attention to the compiler and everything would “just work”. However, there is still a long way to go to achieve this goal.
As more and more companies seek to run ML models on edge devices, more and more hardware is available to run ML models, and more and more compiles are being developed to make ML models run better on hardware accelerators — e.g. MLIR dialects, TVM, XLA, PyTorch Glow, cuDNN, etc. According to PyTorch founder Soumith Chintala, as ML’s adoption matures, the competition between companies will shift to who can better compile and optimize the model.

Understanding how the compiler works can help you choose the right compiler to maximize the performance of your model on the hardware of your choice. It can also help you diagnose model performance problems and speed up model performance.
This article gives a general introduction to the ML compiler. ML compilers began with the rise of edge computing, which made compilers no longer the preserve of systems engineers but the domain of the entire ML profession. If you already know the importance of running ML with an edge device, you can skip the first part of this article.
Then I’ll cover the two main issues of deploying the ML model on edge devices: compatibility and performance, and show how the compiler addresses these issues and how it works. The article concludes with references on how to significantly speed up your ML model with a few lines of code.
1 Cloud computing vs. edge computing
Imagine that you have trained an excellent ML model that is far more accurate than you could ever hope for, and you can’t wait to deploy the model for users to use.
The simplest approach is to package the model and deploy it through a hosted cloud service, such as AWS or GCP, which is what many companies did when they first started using ML. Cloud services contribute greatly in this regard, making it easy for enterprises to put ML models into production.
However, cloud deployments also have many drawbacks. The first is cost. ML models require a lot of computation, which is expensive. Back in 2018, big companies like Pinterest, Infor, Intuit, and others were spending hundreds of millions of dollars a year on cloud services. For small and medium-sized companies, the figure can range from $500 million to $2 million a year. One misstep in cloud services can lead to a startup going out of business.
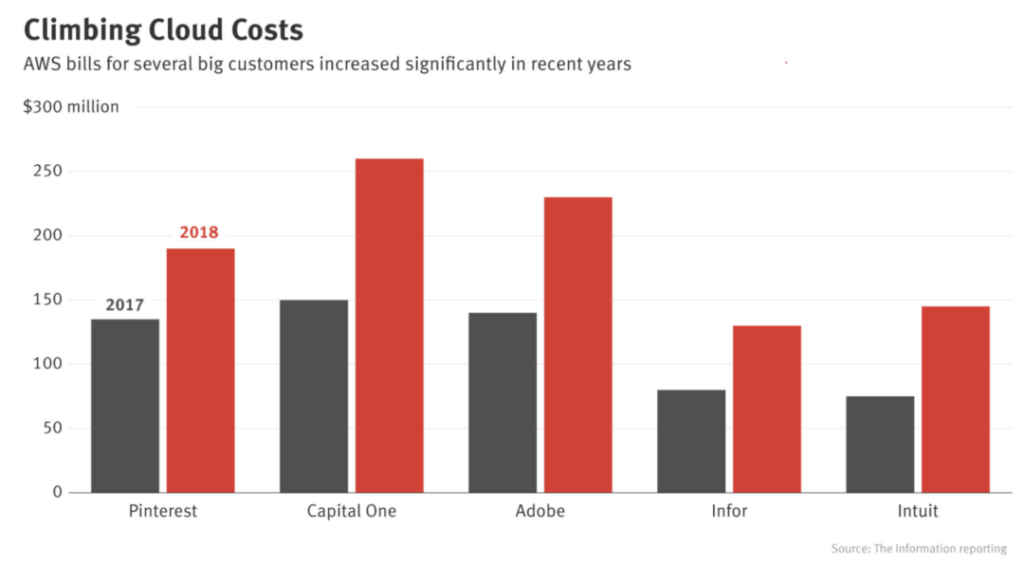
As the cost of cloud computing continues to climb, more and more companies are trying to move computing to consumer devices (edge devices). The more computing is done on edge devices, the less cloud services are needed and the less they have to pay.
In addition to reducing costs, edge computing has many advantages. First of all, edge computing is more scalable. When the model is on the public cloud, sending and receiving data to the cloud depends on a stable network connection. But edge computing allows the model to continue to operate even when there is no network connection or an unstable connection, such as in rural areas or developing countries.
Secondly, edge computing can reduce network latency. If you have to use a network to transfer data (a model that sends the data to the cloud for prediction, and then sends the prediction back to the user), then some use cases may not be realized. In many cases, network delays are worse than inference delays. For example, you might be able to reduce the inference latency of the ResNet50 model from 30 milliseconds to 20 milliseconds, but the network latency can be as high as several seconds, depending on your network.
Third, edge computing can better protect sensitive user data. The ML model of cloud computing means that user data may be sent over the network, increasing the risk of data interception. Cloud computing also stores many users’ data in the same place, which means that a data breach could affect many people. As Security magazine reported in 2020, Nearly 80% of the company over the past 18 months has encountered cloud data leakage (https://www.securitymagazine.com/articles/92533-nearly-80-of-companies-experienced-a-cloud-data -breach-in-past-18-months). Edge computing allows companies to transfer and store user data more securely, avoiding data protection regulations such as GDPR.
2 Compilation: Compatibility
Edge computing has many advantages over cloud computing, so many enterprises are racing to develop edge appliances optimized for different ML use cases. Google, Apple, Tesla and other well-known giants have all announced their own chips. Meanwhile, a number of ML hardware startups have raised billions of dollars to develop better AI chips.
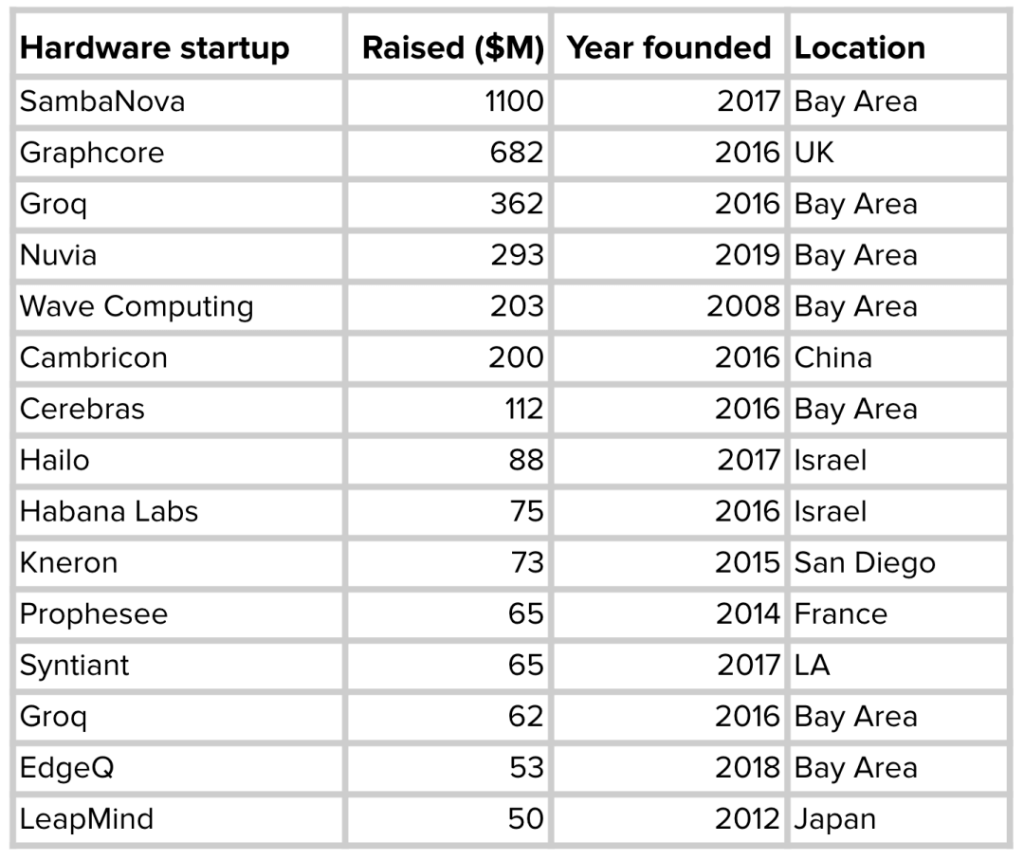
As more hardware products run ML models, the question arises: how do you make a model built with any framework run on any hardware?
For a framework to run on certain hardware, it must be supported by the hardware vendor. For example, although Google publicly released Tpus back in February 2018, PyTorch wasn’t supported until September 2020. Previously, if you wanted to use Tpus, you had to use Google’s TensorFlow or JAX.
It takes a lot of time and effort to get a piece of hardware (or platform) to support a framework. Mapping ML workloads to hardware requires understanding and leveraging the hardware’s infrastructure. However, there is a fundamental problem that must be overcome: Different hardware types have different memory layouts and computation primitives, as shown below:
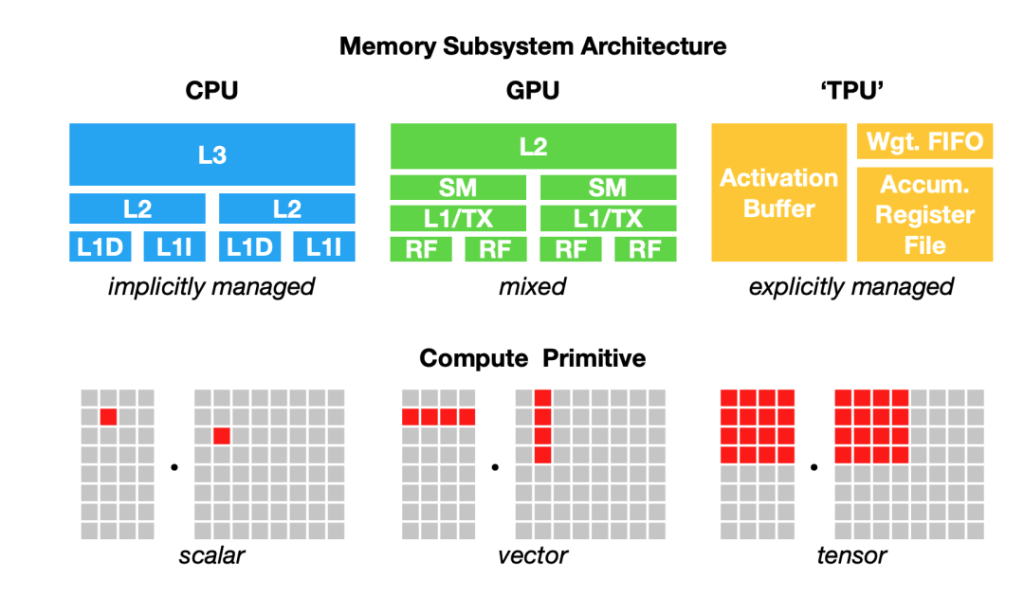
For example, once upon a time, the computation primitive of a CPU was a number (scalar), that of a GPU was a one-dimensional vector, and that of a TPU was a two-dimensional vector (tensor). However, many cpus today have vector instructions, while some Gpus have a two-dimensional tensor core. Given a batch of 256 images x 3 channels x 224 W x 224 H, if you want to perform a convolution operator on this batch, the one-dimensional vector computation primitive will be very different from the two-dimensional vector computation primitive. Also, consider the different L1, L2, and L3 layouts and buffer sizes so that memory can be used efficiently.
Because of this, framework developers tend to support only a few server-level hardware (such as GGPU), and hardware vendors tend to provide their own kernel libraries to only a few frameworks (for example, Intel’s OpenVino library supports Caffe, TensorFlow, MXNet, Kaldi, and ONNX. NVIDIA has CUDA and cuDNN. Deploying ML models to new hardware, such as mobile phones, embedded devices, FPgas, and ASics, requires significant manpower.
Intermediate representation (IR)
Instead of having a new compiler and library for each new hardware type and device, why not create an intermediary to bridge the framework and platform? Framework developers will no longer need to support every type of hardware, but will simply “translate” their framework code into this medium. In this way, hardware vendors only need to support an intermediate framework.
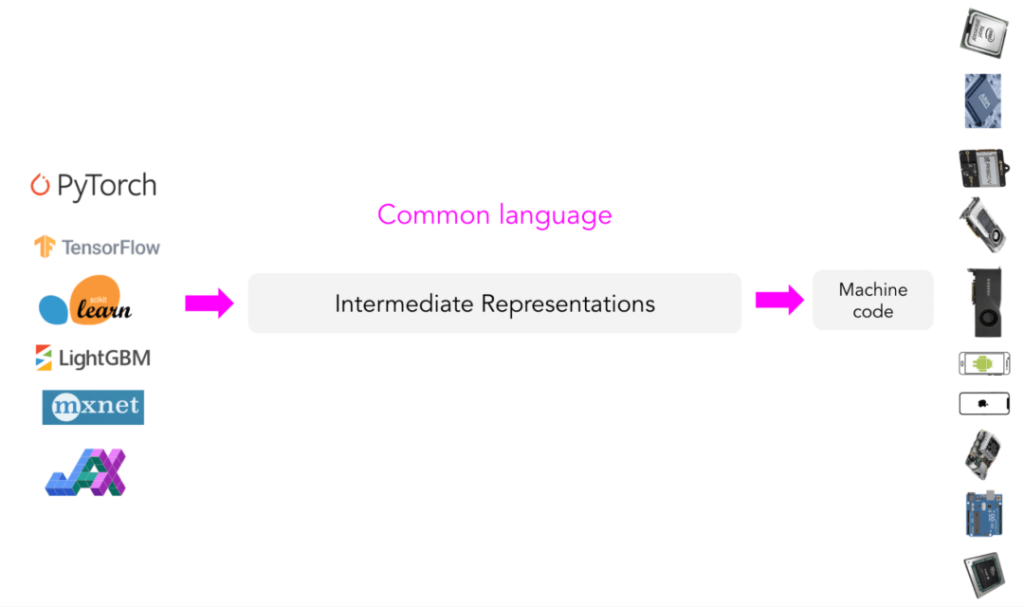
This intermediate medium is called the intermediate representation (IR). IR is the core of what compilers do. The compiler generates a series of high-level and low-level intermediate representations based on the model’s original code, and then generates hardware native code to run the model on a particular platform.
Compilers typically utilize code generators (codegen) to generate machine native code from IR. The most common code generator in ML compilers is LLVM, developed by Vikram Adve and Chris Lattner, which has changed our understanding of systems engineering. LLVM is used by TensorFlow XLA, NVIDIA’s CUDA compiler (NVCC), MLIR (a meta-compiler for building other compilers), and TVM.
Code generation is also known as the “lowering” process, because higher level framework code “lowers” to lower level hardware native code. To be precise, this process cannot be called “translation” because there is no one-to-one mapping between the two types of code.
Advanced IR is usually a computational diagram of the ML model. For those familiar with TensorFlow, the diagram is similar to the diagram in TensorFlow 1.0, before TensorFlow switched to Eager Execution mode. TensorFlow 1.0 builds model computations before running models. Computations allow TensorFlow to understand models and optimize runtime.
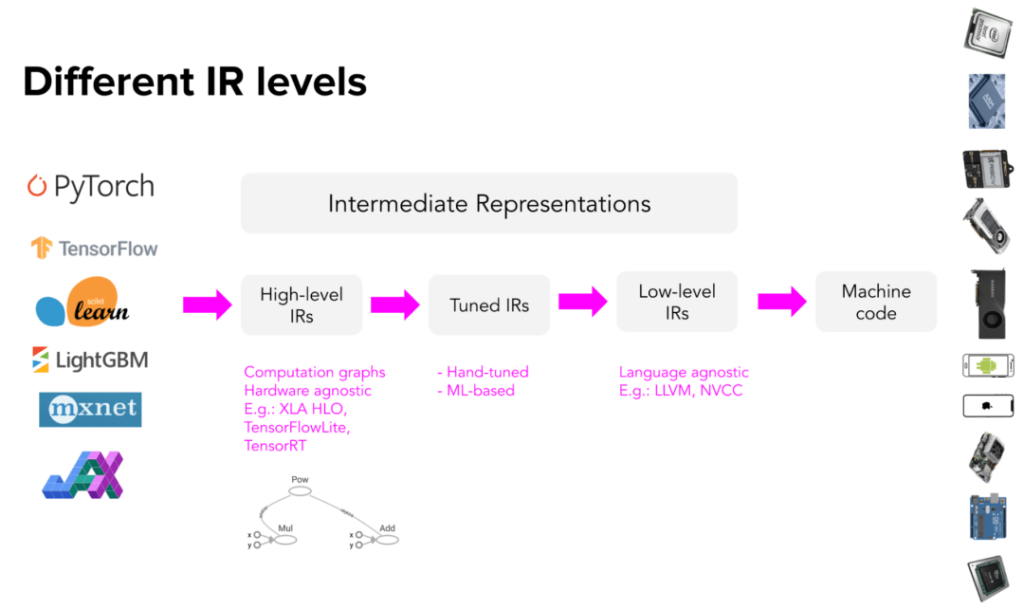
High-level IR is usually hardware-independent (no matter what hardware it is running on), while low-level IR is usually framework-independent (no matter what framework the model is built in).
3 Optimization: Performance
Once the code is “degraded,” you may also experience performance problems running the model on the hardware of your choice. Codegen is very good at demoting IR to machine code, but machine code may not run well enough due to the target hardware backend. The generated code may not take full advantage of data locality and hardware caching, or it may not take advantage of advanced features that speed up the code, such as vector operations or parallel operations.
A typical ML workflow uses a number of frameworks and libraries. For example, Pandas/Dask/Ray is used to extract features from data. Perform vectorization with NumPy; Tree models such as LightGBM are used to generate features, which are then predicted with various models built from different frameworks such as sklearn, TensorFlow or Transformers.
While individual functionality within these frameworks may be optimized, cross-framework optimization is almost non-existent. A simple approach is to move the data to different functions and calculate separately, but this can slow down the overall workflow by an order of magnitude. A study by researchers at Stanford’s DAWN Lab found that: Compared with the manual optimization code, use NumPy, Pandas and typical ML TensorFlow workload in a thread running slower 23 times.
In production, data scientists /ML engineers often use PIPs to install the packages they need to do their jobs, and they deploy their models to production as they perform well in the development environment. When they encounter performance issues in production, their company often hires optimization engineers to optimize the model against the running hardware.


Optimization engineers, however, are scarce and pay high because the job requires knowledge of machine learning as well as hardware architecture. An alternative is to use a Optimizing Compiler, which is a compiler that optimises the code but also automatically optimises the model. In the process of demoting ML model code to machine code, the compiler can analyze the model computation diagram and the operators (such as convolution operators, loop operators, cross entropy, etc.) contained therein, and then try to speed up the computation.
To summarize: the compiler can bridge the ML model to the hardware it runs on. Optimizing the compiler consists of two parts: degradation and optimization. The two parts can sometimes be combined. Optimization can occur at any stage from advanced IR to low IR.
Degradation: The compiler generates hardware native code for the model to run on specific hardware.
Optimization: The compiler optimizes the model based on the hardware environment.
4 How to optimize the ML model
There are two ways to optimize ML models: local optimization and global optimization. Local optimization refers to an optimization model or a group of operators; Global optimization is the end-to-end optimization of the entire graph.
There are some standard local optimization methods, most of which accelerate models by increasing parallelism or reducing chip memory access. Here are four common ones.
Vectorization: Given a loop or nested loop, but executing more than one element at a time, hardware primitives are used to execute multiple elements consecutively in memory.
Parallel: Given an input array (or an n-dimensional array), divide it into different independent blocks of work and perform operations on each block separately.
Loop Tiling: Modify the order in which data is accessed in the loop to make better use of the hardware’s memory layout and cache. This optimization method is extremely hardware dependent. Access patterns that work for cpus may not work for Gpus. Details can be found in the visual explanation provided by Colfax Research
Operator fusion: Multiple operators are fused into one operator to avoid redundant memory access. For example, two operations on the same array need to be looped twice, but only once after fusion. See the example provided by Matthias Boehm for details.


Shoumik Palkar, creator of the Weld compiler optimizer, said that under certain conditions, these standard local optimizations can improve model performance by about three times. (https://www.youtube.com/watch?v=JbTqNuCIJM4)
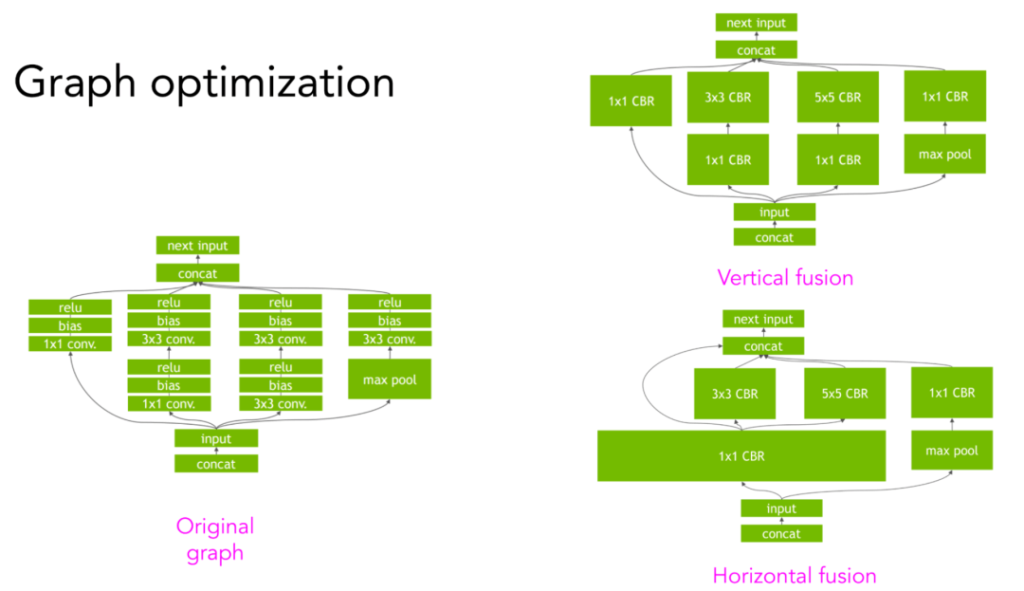
Achieving greater speed gains requires higher levels of structure in the graph. For example, given a convolutional neural network and its computational graph, vertical or horizontal fusion can be carried out to reduce memory access and speed up model operation. Details refer to the NVIDIA TensorRT team provide visual interpretation (https://developer.nvidia.com/tensorrt).
5 Human design vs. ML based compilers
Manual design optimization rules
As shown in the vertical/horizontal fusion example above, there are many ways to perform computation diagrams. For example, given three operators A, B, and C, one can fuse A with B, B with C, and also A, B, and C.
Often, optimization engineers at frameworks and hardware vendors can find out empirically the best way to perform model computation diagrams. For example, NVIDIA might have an engineer or even a team of engineers dedicated to figuring out how to make the ResNet-50 model run faster on NVIDIA’s DGX A100 servers (so, Should not be too seriously MLPerf benchmark results (https://mlcommons.org/en/inference-datacenter-10/). Because even if a common model can run fairly fast on some hardware, it doesn’t mean that any model using that hardware will achieve the same high speed. This model may just be over-optimized).
Manual design optimization rules have some shortcomings. First, the resulting optimization rules may not be optimal. There is no guarantee that the optimization method the engineer comes up with is the best solution.
Secondly, the artificially designed optimization rules are not self-adaptive. If you want to optimize the model for a new framework or a new hardware architecture, you have to re-invest a lot of manpower.
Moreover, model optimization depends on calculating the operators in the graph, which adds complexity. Optimizing convolutional neural networks is different from optimizing recursive neural networks, which in turn is different from optimizing Transformer model. NVIDIA and Google have focused on optimizing common models like ResNet and BERT for their own hardware. But what if ML researchers invent a new model architecture? They will have to optimize the new model themselves and prove it has high performance before hardware vendors can adopt and continue to optimize the model.
Use ML to accelerate the ML model
Our goal is to find the fastest way to execute the graph. Can we try all the possible methods, record the running time of each method, and then find the one with the shortest time?
Yes. The problem is that there are simply too many potential approaches and combinations to exhaust. But what about using ML?
With ML, you can narrow the search space (that is, the set of all possible methods) without having to try everything.
Using ML also allows you to predict how long each method will take without wasting time waiting for the diagram to complete execution.
However, it is very difficult to estimate how long it will take for a particular method to execute the graph because it requires a lot of assumptions about the graph. Current technology can only focus on a small part of the graph.
If you’ve ever run PyTorch on a GPU, you’ve seen the following Settings:
torch.backends.cudnn.benchmark=True
When set to True, cuDNN autotune is enabled. cuDNN autotune explores the fastest of a set of preset ways to perform the convolution operator. If the shape of the convolutional neural network is consistent from iteration to iteration, enabling cuDNN autotune can greatly improve efficiency. In addition to running the convolution operator slowly the first time (because cuDNN autotune takes time to explore the fastest method), cuDNN can use autotune’s cache results to directly select the fastest configuration in subsequent runs.
While cuDNN autotune can improve efficiency, it only works with convolution operators and should only work with PyTorch and MXNet. A more general solution is autoTVM, which is part of the open source compiler stack TVM. autoTVM searches for the best execution for subgraphs, not just for an operator, so its search space is much more complex. How autoTVM works is also complicated, but it can be summarized as follows:
1. Divide the calculation graph into multiple subgraphs.
2. Predict the size of each subgraph.
3. Allocate time to find the best execution method for each subgraph.
4. Combine the best execution methods of each subgraph and execute the entire calculation graph.
autoTVM calculates the actual running time of each method, collecting real data that can be used to train the cost model to predict how long a future method will take. The advantage of this approach is that since the cost model is trained on the data generated at run time, it can be adapted to any hardware, and the disadvantage is that it takes longer to wait for the cost model training to complete.
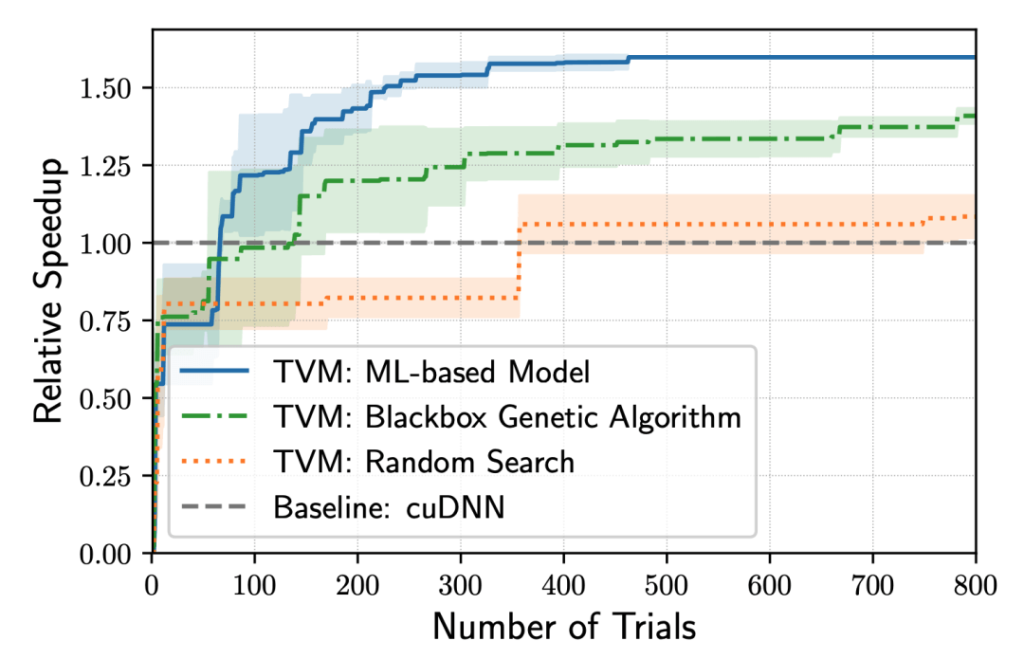
The speed increase from the ML-based TVM (based on the speed of cuDNN running the ResNet-50 model on NVIDIA TITAN X); Ml-based TVM takes about 70 iterations to surpass cuDNN’s performance; Experimental data came from Chen Tianqi et al.
Compilers like TVM are adaptive and flexible, allowing users to easily try out new hardware, such as the M1 chip released by Apple in November 2020.
M1 is a system-on-chip (SoC) based on ARM. We are more or less familiar with the ARM architecture of M1. However, the ARM implementation of M1 still has many novel aspects and requires a lot of optimization to make various ML models run quickly on M1 chips.
A month after the M1 chip was released, OctoML The TVM team, founded in 2019, focuses on the deployment of ML models, autoTVM’s optimizations are much faster than those manually designed by Apple’s Core ML team 30% (https://venturebeat.com/2020/12/16/octoml-optimizes-apache-tvm-for-apples-m1-beats-core-ml-4-by-29/). Of course, as M1 matures and human optimization deepens, it will be difficult for automatic optimization to surpass human optimization, but system engineers can still use automatic optimization tools such as autoTVM to accelerate optimization.
While auto-tuning works well, there is one problem: TVM can be slow. You need to try all possible approaches to determine the optimal optimization path, a process that can take hours, or even days for complex ML models. But this is done once and for all, and the results of optimized searches can be cached and then used to optimize existing models, as well as provide a basis for future optimizations.
When you optimize the model once for a hardware backend, the model can run on multiple devices using the same hardware backend. This optimization is very useful when you have a model ready for production and you have selected the target hardware to run your reasoning on.
6 Different compilers
The most widely used type of compiler today is a domain-specific compiler developed by the major frameworks and hardware vendors for a particular combination of frameworks and hardware. Not surprisingly, the most commonly used compilers are developed by the largest frameworks and hardware vendors.
NVCC (NVIDIA CUDA compiler) : closed source; CUDA only.
XLA (Accelerated Linear Algebra Compiler, by Google) : Open source as part of the TensorFlow library; XLA was originally intended to accelerate the TensorFlow model, but has been used with JAX.
PyTorch Glow (Facebook) : Open source as part of the PyTorch library; Although XLA+PyTorch is enabled on Tpus, PyTorch Glow is still relied upon for other hardware.
Third-party compilers are often ambitious (it takes a lot of confidence for a compiler developer to think they can model Gpu-optimized better than NVIDIA). Third-party compilers are important because they can help smaller companies deliver new frameworks, new hardware, and new models with lower overhead and better performance, even as the big names have tweaked their compilers for their products.
The best third-party compiler in my mind is Apache TVM, which works with a variety of frameworks (including TensorFlow, MXNet, PyTorch, Keras, CNTK) and a variety of hardware backends (including CPU, server GPU, ARM, x86, mobile GPU, and FPGA-based accelerators).
Another project I like is MLIR. It was also originally initiated at Google by LLVM creator Chris Lattner, but now the project is part of LLVM. MLIR is not really a compiler, but rather a meta-compiler, an infrastructure that allows users to build their own compilers. MLIR can run a variety of IRS, including TVM IR, LLVM IR, and TensorFlow compute graph.
WebAssembly (WASM)
WASM is one of the tech trends I’m most excited about over the past few years. It has high performance, is easy to use, and its ecology is growing fast. As of September 2021, 93% of devices worldwide support WASM.
We have been discussing how the compiler generates machine-native code for the model to run on a particular hardware back end. Can you generate code that can run on any hardware back end?
Browsers have one advantage: if your model can run in a browser, then that model can run on any browser-enabled device, including Macbooks, Chromebooks, iphones, Android phones, etc., without caring what chip those devices use. If Apple decides to switch from Intel to ARM chips, it won’t affect you.

WASM is an open standard that lets you run executables in a browser. Once you’ve built a model using frameworks like sklearn, PyTorch, TensorFlow, etc., you don’t have to compile the model for specific hardware. Instead, you can compile the model to WASM. You will then get an executable file that can be executed using JavaScript.
Because WASM runs in a browser, it has the disadvantage of being slow. Although WASM is already much faster than JavaScript, it’s still slow compared to running native code on a device, such as an iOS or Android application. Research by Jangda et al. showed that applications compiled to WASM Its running speed is slower than the native applications, on average, 45% (firefox) to 55% (Google browser) (https://www.usenix.org/conference/atc19/presentation/jangda).
There are many compilers that compile code into the WASM runtime. For example, the most popular Emscripten (which also uses LLVM Codegen) only compiles C and C++ to WASM; Scailable compiles the scikit-learn model to WASM, but it only has a dozen stars on GitHub and hasn’t been updated in months (is it no longer maintained by the developer?). ; TVM should be now can also use the only one to compile a ML model WASM compiler (https://tvm.apache.org/2020/05/14/compiling-machine-learning-to-webassembly-and-webgpu ).
Tip: If you plan to use TVM, it can be quickly installed using the unofficial conda/pip command (https://tlcpack.ai/). Don’t look at the Apache site for instructions. Because if you follow the latter operation problem, only to find help on their Discord (https://discord.gg/8jNs8MkayG).
7 The future of compilers
It is important to think about the details of how models run on different hardware backends to help improve model performance. Austin Huang (https://www.linkedin.com/in/austin-huang-74a75422/) in MLOps Discord on post said, just use simple tools available, Quantization tools, Torchscript, ONNX, TVM, etc., often get twice as much model acceleration.
Here I recommend an article (https://efficientdl.com/faster-deep-learning-in-pytorch-a-guide/), it lists several on the GPU acceleration PyTorch model useful skills, don’t even have to use the compiler.
During the model deployment phase, it is necessary to try different compilers and compare which one provides the best performance improvement. You can do experiments in parallel. If one inference request gets a small speed boost, millions or billions of inference requests can add up to a big payoff.
While compilers for machine learning have come a long way, there is still a lot of work to be done to abstract the compiler away from the general ML profession. Ideally, the ML compiler would be like the GCC traditional compiler. GCC automatically relegates C or C++ code to machine code, letting most C programmers not care what intermediate representation GCC produces.
In the future, it is believed that ML compilers will be able to do the same. When a developer uses the framework to create an ML model in the form of a computational graph, the ML compiler can then generate machine native code for the model based on any target hardware, and the developer does not have to care what intermediate representation the compiler generates. Tools like TVM can help us achieve this future.